

The Challenge
The European Union is introducing the General Data Protection Regulation on May 25 2018. This new law has been called the world’s strongest and most far-reaching law aimed at strengthening citizens' fundamental rights in the digital age. The new law applies to any organization processing personal data about a citizen or resident in the EU regardless of that organizations’ location. It is definitely a force to be reckoned with as the fines for non-compliance are extremely high.
Many of the law’s Articles deal with how personal data are collected and processed and include a special emphasis, guidelines and restrictions on what the EU calls “automatic profiling with personal data”. So what has that to do with us data scientists? Many of us use methods and machine learning to create new fact-based insight from the customer or personal data that we collect so that we can take decisions, possibly automatically. So the law applies to us. But that Customer Intelligence we create is fundamental for the successful running of our organizations business.
Does this mean this new force will put limits on what we do? Or even worse, does it mean that we have to go over to the dark side to help our businesses? Absolutely not! The new law defines that we must gain permission, perform tests, and document. In no way does it restrict what honest data scientists can do. If anything, it provides us with opportunities.
Topic. GDPR meets Customer Intelligence
Challenge. Apply machine learning algorithms to create new fact-based insights taking the new GDPR into account
The Experiment
Distilling the GDPR down for data scientists means we need to look at six topics:
- Identify fields of information we will use that contain personal data
- Identify any fields of information that contain “special categories of data” (i.e.: those that could discriminate)
- If any special categories of data exist, ensure that there are no highly correlated fields that could mimic the special categories
- Possibly anonymize any personal data so that the GDPR regulations do not apply and …
- …Explain an automatic processing decision (or a model or rule in our case) in a way that is understandable
- Document our process that uses all of these data for “automatic processing”
Figure 1. This workflow shows an example of analyzing customer data while adhering to GDPR.
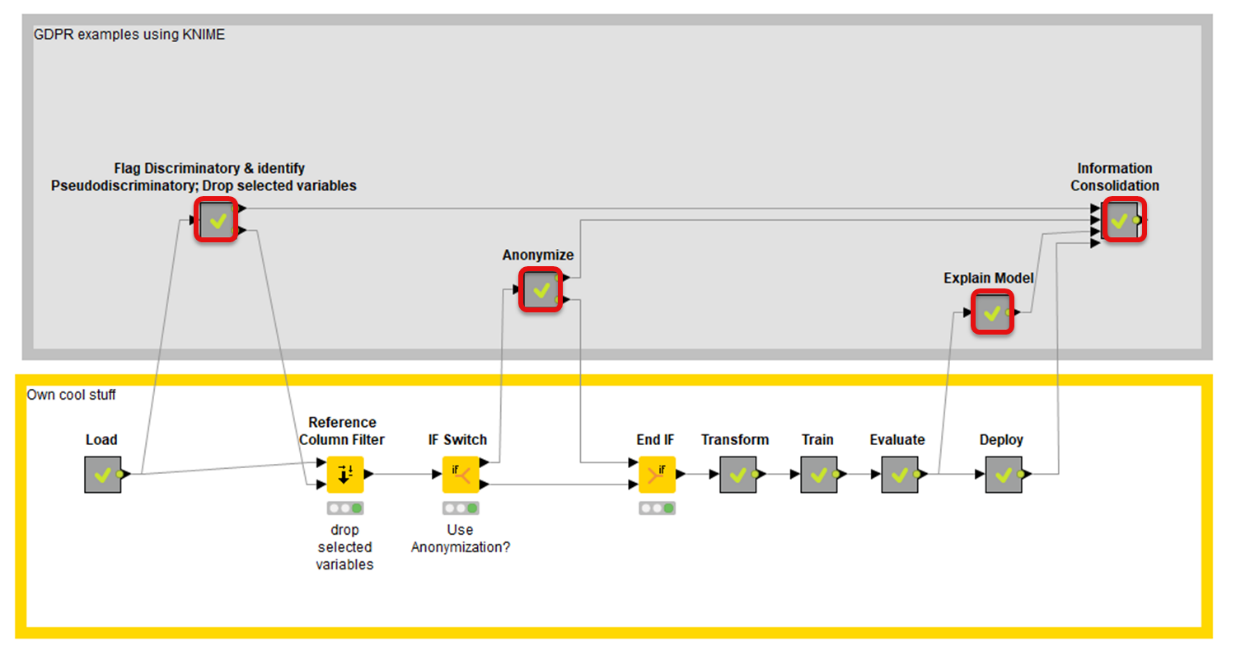
And that is exactly what we do. Since the details of each of these steps and the appropriate workflow examples goes far beyond a blog, you can get a full white paper as well as KNIME public server examples.
- Download GDPR example workflows from the KNIME Hub
- Read the whitepaper "Taking a proactive approach to GDPR with KNIME"
If we then go on to use the KNIME Server, we can have these standard workflows available for anyone doing work on personal data.
The Results
While the GDPR does introduce new requirements that many of us will need to follow if we are using personal data, in no way does it limit us. If anything, it allows us to surface to our management and others within our organization, showing that what we do with customer intelligence using KNIME is well thought through, well documented, and fully supportive of our organization’s GDPR requirements – so yes, Customer Intelligence and the GDPR blend! Definitely not the Dark Side at all!
You might also like …
If you enjoyed this, you might like Phil Winter’s (a.k.a. Darth Vader) speech “GDPR – A Proactive Approach” at our recent KNIME Spring Summit in Berlin.
--------------------------------------------
In the Will They Blend? blog series we experiment with the most interesting blends of data and tools. Whether it’s mixing traditional sources with modern data lakes, open-source devops on the cloud with protected internal legacy tools, SQL with noSQL, web-wisdom-of-the-crowd with in-house handwritten notes, or IoT sensor data with idle chatting, we’re curious to find out: will they blend? Want to find out what happens when IBM Watson meets Google News, Hadoop Hive meets Excel, R meets Python, or MS Word meets MongoDB?
Follow us here and send us your ideas for the next data blending challenge you’d like to see at willtheyblend@knime.com.