
Large language models (LLMs) are advanced artificial intelligence systems that understand and generate human-like text. They’re trained on huge amounts of data from the internet, research papers, and books so that they can generate new sentences. You can have a conversation with them, get them to answer questions, write poems, create images, and even translate your text.
They’re currently reshaping the world of data analytics. In this blog post, we will learn about large language models, particularly
Let's dive into it!
How do LLMs work?
LLMs are characterized by their large number of parameters compared to smaller models and traditional machine learning models.
Let’s consider that you want to bake a cake. The recipe you use is like the algorithm for a machine-learning model. The ingredients and their quantities are like the parameters of the model. In a smaller model or a traditional machine learning model, you would have only a few ingredients to work with. For example, you bake a cake with just flour, sugar, eggs, and baking powder. These ingredients represent the basic settings or parameters that the model uses to learn and make predictions.
On the other hand, with a large language model (LLM), you have a lot more ingredients to work with. In addition to the flour, sugar, eggs, and baking powder, you can also use chocolate chips, vanilla extract, nuts, and other flavorings. These additional ingredients represent the extra parameters in the LLM.
Parameters are like the inside settings that help make the models better while they are learning and practicing. This helps the LLM to learn patterns from data and enables it to capture intricate language structures and nuances and generate highly coherent and contextually relevant responses. The more parameters a model has, the better it will perform; hence, the growing tendency for models to become larger and larger.
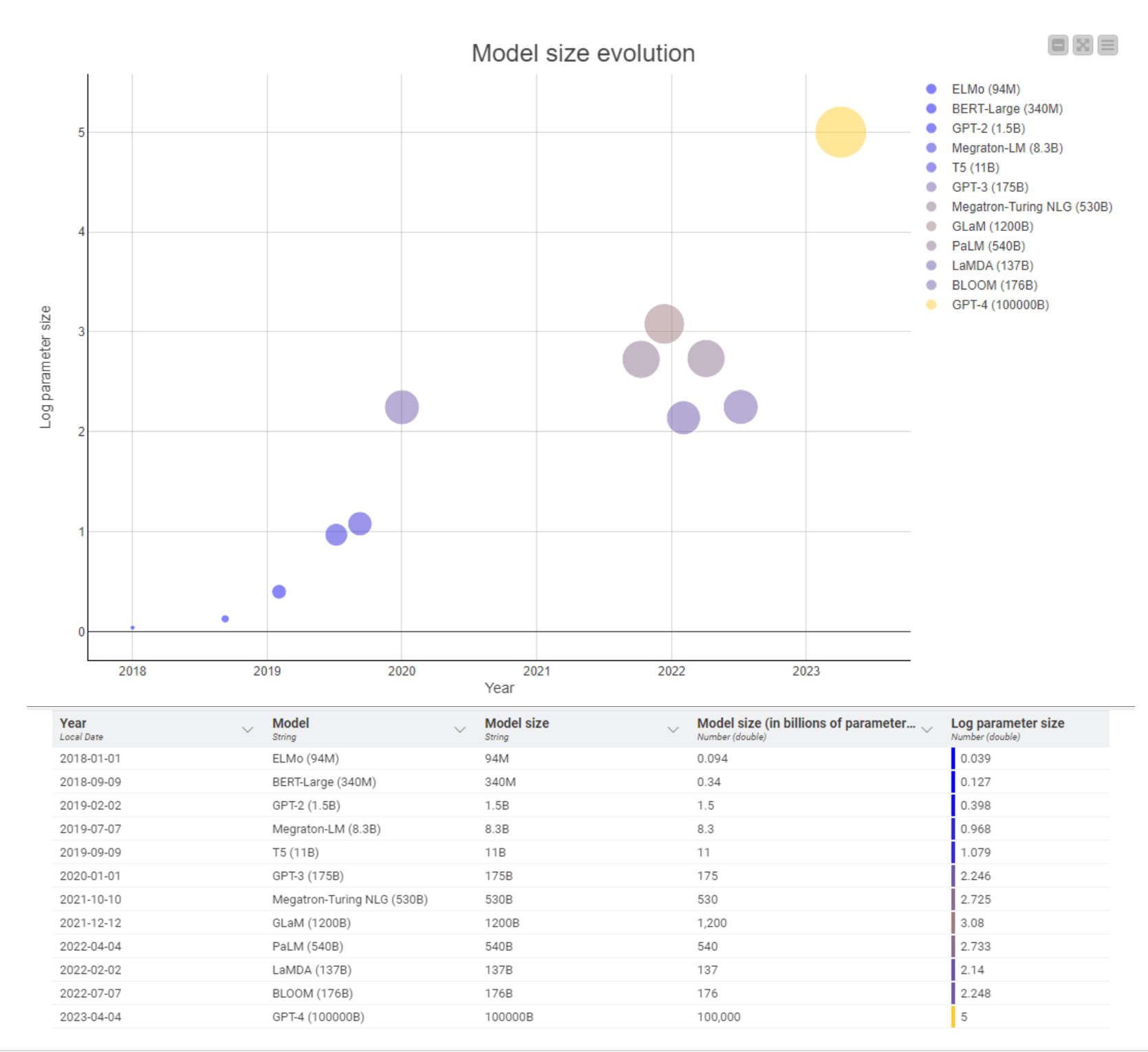
See the evolution from language models to large language models in the graphic below. In just 5 years, the number of parameters has gone from 94 million to 100,000 billion parameters.
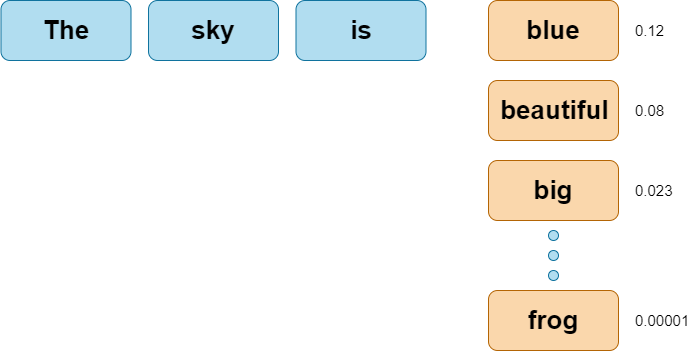
An LLM is trained to suggest the most likely next word or phrase based on previous extensive exposure to similar contexts. It simply gives you the most probable answer based on the number of parameters from which it learned.
For example, if we type “the sky is …'', the most probable follow-up word would be “blue”. This is because the model was trained on millions of texts and learned “blue” to be the best next token.
A "token" is a unit of text that a language model processes. It can be a word, a subword, or even a character, depending on how the model is configured. This proficiency enables the LLM to provide the most probable answer to a question.
The reliability of the answers depends on the diversity and quality of the data the LLM was trained on. If the training data covers a broad range of topics and is of high quality, the model is more likely to generate accurate and informative responses.
It is, however, crucial to note that these types of technologies possess only syntactic knowledge and lack semantic understanding. This means that the LLM can understand how words can be combined into sentences that make sense. But it doesn’t know the meaning behind the text it generates in the same way humans do.
For instance, while the LLM can correctly answer a simple arithmetic question like "1+2" as "3," that doesn’t mean it understands how addition works. For addition, multiplication, or any other calculation, the AI relies on patterns it learned during training to recognize and generate the most probable answer, which, in this case, is "3." For the same reason, AIs are usually not capable of tackling more complex calculations. They need to be specifically enhanced with additional capabilities or external extensions.
What are Large Language Models used for?
Large Language Models have gained immense traction in recent years. This is because they are so good at understanding and generating natural language, and simulating human conversational behaviors. Some of the best-known LLMs include OpenAI’s ChatGPT, Meta’s LLaMA, and Google’s Bard. They are versatile tools that can be used in various domains, such as
- Chatbots: LLMs can power chatbots, e.g. in customer service to answer questions
- Content generation: LLMs are good at generating human-like text, e.g. in marketing to write articles, emails, etc
- Language translation: LLMs can accurately convert text from one language to another
- Sentiment analysis: Analyzing the sentiment or emotion expressed in a piece of text
- Code generation: LLMs can assist in generating code snippets based on natural language descriptions, making coding tasks more accessible.
What factors affect how an LLM performs?
LLMs are rapidly taking over the world of analytics and revolutionizing various aspects of our lives and work. It is important to understand what makes them so powerful and what can influence their performance. The strength of LLMs comes from three primary factors:
Factor 1: Data Quality and Quantity
LLM models are powerful because they've learned a lot from reading a variety of texts, sources, and documents. High-quality data ensures that the LLM learns accurate and representative language patterns. Clean, well-labeled data reduces noise and biases, leading to better generalization and performance.
Training the LLM with a higher quantity of data typically leads to better performance. Since it allows the model to learn from a diverse range of linguistic contexts. Large datasets provide various examples for the model to learn from and help prevent overfitting by capturing a wider distribution of language features.
Overfitting is when the machine learning model becomes too focused on the specific examples in the training data and fails to generalize well to new, unseen examples. It essentially "memorizes" the training data rather than learning the underlying patterns and relationships, which can result in poor performance when applied to real-world tasks.
To learn more about overfitting- Watch our Data Science Pronto video!
Using a diverse range of topics, genres, and languages while training the LLM ensures that the model can handle various linguistic tasks effectively. Diversity in the training data helps the model get better at handling new situations and unseen examples. This makes it stronger and more dependable when dealing with different kinds of situations. In other words, it can provide reliable and good answers or predictions on a wide range of topics or areas, from aircraft maintenance to opera singing!
OpenAI's chatbot was trained using an impressive 570 gigabytes of text gathered from diverse and reliable sources, such as academic papers and books. Additionally, these models can continue to learn and enhance their language abilities through interactions with people who use the LLM.
Factor 2: Model Architecture
The way LLMs are built is important because it affects how well they can understand the complex way people communicate. LLMs are mainly built upon the groundwork established by transformers.
Transformer-based architecture can capture complex relationships between words. They are a class of so-called “deep neural networks”. Transformers achieve this through a mechanism known as self-attention. Self-attention allows the model to weigh the importance of each word in a sentence in relation to every other word.
Unlike traditional neural networks, which process words sequentially, transformers can simultaneously consider all words in a sentence. This means they can understand subtle relationships between words, even if the words are far apart in the sentence.
Self-attention enables the model to capture long-range dependencies and contextual information efficiently, leading to improved performance in tasks like text generation, translation, and sentiment analysis.
The detailed understanding of contextual relationships allows transformers to recognize slight differences in meaning, resulting in more accurate and relevant responses. This unique mapping capability through self-attention is a fundamental reason why LLMs having a transformer-based architecture are so effective in tasks that require a deep understanding of natural languages.
Factor 3: Quality of the Training Routine
The training phase is one of the most critical components in the development of LLMs. Training an LLM from scratch is a computationally intensive task because it requires substantial computational resources - power, time, and data. It often requires specialized hardware and data centers due to the massive scale of the model. The high complexity of LLMs makes training a model from scratch so expensive that it's mainly feasible only for big tech companies.
Having a high-quality training routine empowers the model to identify and understand complex patterns in data, enabling it to produce dependable and contextually appropriate responses.
LLMs’ vast neural network architecture comprises hundreds of billions of parameters, which represent the model's learned knowledge. During training, these parameters continually evolve and adapt to optimize the model's performance.
One notable technique used during training is "autoregressive modeling," where the model learns to predict the next word in a sentence based on the previous one. This approach allows the LLM to grasp the connections between words in different contexts, enhancing its ability to understand language at an advanced level.
Risks and limitations of LLMs
Even though LLMs bring unquestionable benefits and numerous possibilities, it is important to remember that LLMs come with considerable drawbacks that require careful attention.
Transparency challenges in LLMs
LLMs are often referred to as "black box" models. This is because they are so complex and a person can't look inside and comprehend the decision-making process. In certain fields like banking or insurance, having a transparent process can be beneficial. Due to this, the use of black box models is sometimes completely restricted.
The difficulty in understanding the reasons behind AI decisions creates the possibility of unnoticed errors. Consider, for instance, an AI system trained on historical data containing traces of racial or gender discrimination in determining who qualifies for insurance. In such a case, the system might unintentionally reinforce biased patterns, leading to decisions based on incorrect assumptions. Identifying and addressing these biases can be extremely difficult, if not impossible.
To understand the results of complex black box models, the field of Explainable AI (XAI) was developed. XAI focuses on clarifying complex models by using simpler ones, often utilizing decision trees or linear models.
These models depend on shallower architectures that are simpler for us to follow and understand. Despite commendable efforts and remarkable progress in this domain, keeping up with the continuously growing complexity of newly created and updated LLM models remains a difficult and seemingly endless challenge.
Hallucinations, toxic content, and copyright infringement
In addition to explainability, LLMs pose concerns in the form of “hallucinations”. These occur when an AI provides responses not rooted in actual data or real information. They stem from learning errors or misinterpretations of input data. AI hallucinations are hard to detect and they can pose significant harm if they occur in a decision-making process.
Given the elusive nature of hallucinations, it becomes crucial to exercise caution when considering the outputs generated by LLMs. These hallucinations can potentially result in harmful consequences, especially in a professional setting. An example is the generation of harmful content infused with bias and stereotypes. If not identified, this can cause significant harm.
Another scenario with the potential for financial and legal consequences arises when LLMs generate output derived from copyrighted material. This happens because a large portion of their training data is copyrighted. As a result, the AI may reproduce the original training input or fragments of it, leading to serious copyright infringement, rather than creating a genuinely "new" output by combining various sources.
For these reasons, it's good practice not to blindly use what LLMs produce, but to use the output as a starting point to create something truly authentic. This not only decreases the risk of spreading inaccuracies or facing legal problems but also promotes the creation of new and unique content.
Data privacy
Finally, using LLMs through third-party application programming interfaces, APIs for short, raises the concern of potential leakage of confidential data. If we opt for an API from a well-known LLM for its improved performance instead of using a locally developed model, it's important to note that any information we input into the model may become the property of the provider. This data is likely to be used for future training purposes.
Therefore, it is very important to avoid sharing sensitive information during interactions with AI systems. Especially within a corporate setting, local models are preferred despite their potential shortcomings.
Here's how KNIME can help you with your LLM
LLMs represent a relatively recent technological leap that has already exerted a great impact on the world. Some experts push it further suggesting that, in the years to come, AI may become the next world outbreak after the advent of the internet.
KNIME Analytics Platform allows users to access, blend, analyze, and visualize their data, without any coding. Its low-code, no-code interface makes analytics accessible to anyone, offering an easy introduction for beginners, and an advanced data science set of tools for experienced users.
The KNIME AI Assistant (Labs) extension, which is available as of KNIME Analytics Platform version 5.1, can enable you to build custom LLM-powered data apps and do more with your data. Browse through the AI Extension Example Workflows space which offers a curated collection of KNIME workflows, demonstrating practical applications.
If you're new to the KNIME Analytics Platform, there’s no better starting point than downloading the latest software version – it’s open source and free of charge.