
KNIME Analytics Platform's Image Processing extension now includes Vision Transformer models.
You can now use new KNIME nodes for three widely used Transformer models: Vision Transformer (ViT), Swin Transformer, and Pyramid Transformer. These are included in the new Vision Transformer extension, available as an experimental download from the KNIME Community Hub. We also plan to expand this into a broader Media Processing Extension to support other unstructured data types often used in marketing analytics.
This extension was created through an incubator program, with significant technical guidance and financial support from KNIME.
In this article, we introduce Transformer models, explain how the ViT Classification Learner and Predictor nodes function, and demonstrate their application in image classification.
What are transformer models?
The advent of transformer models, with their innovative architecture, has deeply transformed the role and capabilities of artificial intelligence, redefining its abilities across various domains.
Transformer models were originally developed for natural language processing (NLP) tasks. The advancement from recurrent and convolutional models is due to a mechanism known as self-attention. This mechanism enables transformer-based models to consider the significance of different parts of the input data relative to each other, regardless of their position.
This approach, of understanding dependencies within data allows them to achieve a higher level of comprehension.
Consider a sentence like "The quick brown fox jumps over the lazy dog."
A traditional model might process "fox" and "dog" independently, or only in relation to their immediate neighbors. A Transformer model, however, uses self-attention to understand that "fox" is the subject performing the "jumping" action, and "dog" is the object being "jumped over," even though they are separated by several words. This ability to capture long-range dependencies is what gives Transformers their power.
Vision transformers bring self-attention to images
The transformative power of self-attention is not confined to text. Researchers soon recognized its potential for visual data.
This led to the development of Vision Transformers (ViTs).
The core idea behind ViTs is to apply the Transformer's self-attention mechanism to images. Rather than processing an image as a whole, ViT first divides every image into a series of smaller, non-overlapping patches. Subsequently, these image patches are treated in precisely the same manner as words in a sentence: They are converted into embeddings and fed into the Transformer's encoder layers. Just as the Transformer learns relationships between words, the ViT learns relationships between these visual patches.
This allows ViTs to capture not only fine-grained local details within each patch, but also the key global context across the entire image.

A conceptual representation of how a Vision Transformer processes an image. The image is divided into patches, which are then embedded along with positional information. These embeddings are fed into a standard Transformer encoder, utilizing self-attention to understand relationships between patches, before being passed to a classifier.
Vision transformers have quickly demonstrated their viability in image recognition tasks and frequently outperform conventional convolutional neural networks (CNNs) in this field.
Keeping this in mind, we are presenting two additional nodes in the KNIME Analytics Platform that make Vision Transformers' capabilities part of your image analysis workflow:
- ViT Classification Learner
- ViT Classification Predictor
The addition of these new nodes enables end-to-end image classification using transformer-based architectures, making it easier to incorporate cutting-edge deep learning techniques into computer vision projects.
These nodes are part of the Media extension, which can be downloaded from the KNIME Community Hub. Note, this is still an experimental extension. To see it in the list of available extensions, you will need to check the flag "Experimental Extensions" in the Preferences page.
Case study: Classifying images as "friendly" or "hostile"
To demonstrate the potential of the ViT nodes, we designed a workflow particularly aimed at classifying images into two distinct classes: "friendly" and "hostile."
Download this workflow from KNIME Community Hub. The example demonstrates how easily ViT models can be applied to any image classification task.
The dataset used for demonstration purposes contains 100 images, chosen to include 50 examples clearly depicting "friendly" scenarios and 50 examples demonstrating "hostile" scenarios.
In a traditional image classification task, you might need to use a larger number (typically at least 500 per class, depending on how difficult is the classification task) of images, but our application is just for the purpose of demonstrating how the nodes work.

Consider our task of classifying images as "friendly" or "hostile."
A traditional Convolutional Neural Network (CNN), it might identify specific patterns like a smiling face or a weapon by looking at local pixel arrangements.
A ViT, however, would divide the image into patches.
For an image showing a group of people, some holding hands and others with neutral expressions, the ViT's self-attention mechanism might learn that the "holding hands" patch is highly correlated with the "smiling face" patch, and both contribute strongly to a "friendly" classification, even if they are far apart in the image.
Conversely, in a "hostile" image, a patch containing a specific type of debris might be strongly associated with patches showing a damaged structure, leading to a "hostile" classification, capturing a more holistic understanding of the scene.

Workflow architecture and functionality
A comprehensive study of the workflow recommends the following sequential phases:
Table Reader: The workflow starts by loading the image dataset, which is structured as a table. Each row represents an image, either by referencing a file path, or by structuring the image directly inside the table so that it can be used without needing to access the original file again.
ImgPlus to PNG Images: Next, the image data is converted into PNG format using the ImgPlus to PNG Images node. This conversion ensures compatibility with the ViT model, as the downstream nodes expect image inputs in PNG format.
Ungroup and RowID: Some image datasets may store images as grouped data (e.g. in collections or sequences). The Ungroup node separates these into individual rows, ensuring that each row contains a single, independent image.
Partitioning: The Partitioning node systematically splits the dataset into distinct subsets.
- Training set: Used for the training of the Vision Transformer (ViT) model, comprising around 70% of the dataset.
- Validation set: Used for training to monitor the model's performance and tune hyperparameters to prevent overfitting (for instance, made up of 15% of the data).
- Test set: Reserved for objective evaluation of the model's predictive accuracy on new data (e.g. comprising 15% of the data.
ViT Classification Learner: This node offers training data processing for training a Vision Transformer model. The users are provided with the flexibility to fine-tune several parameters, such as choosing a pre-trained ViT base model, specifying training epochs, and tuning learning rates, thus allowing accurate fine-tuning of the model for the task at hand.
ViT Classification Predictor: After training is complete, the ViT Classification Predictor node takes the trained model and applies it to the test set. It outputs classification labels, such as “friendly” or “hostile”, for each image based on the model’s learned patterns.
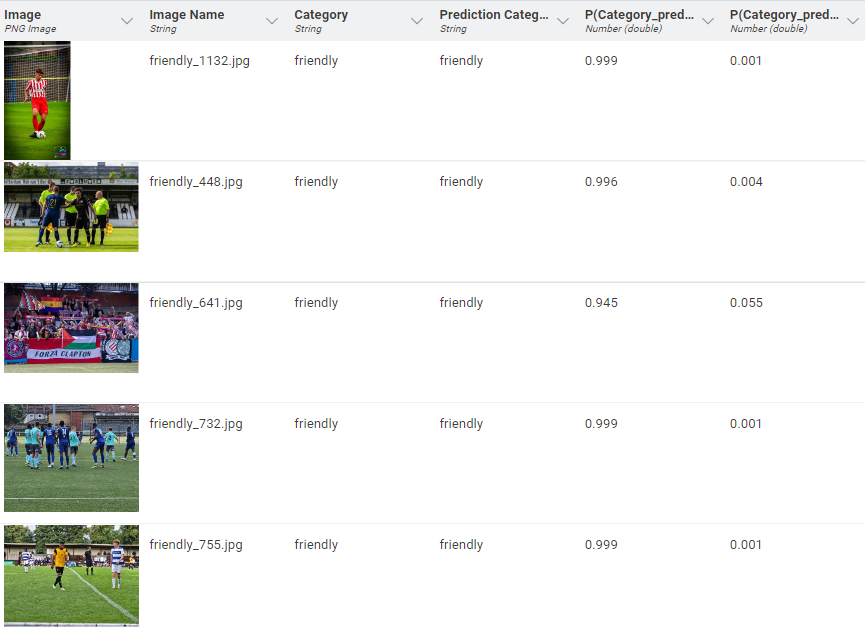
Table View: For a visual check of the results, the Table View node allows users to view the predictions alongside the original image data. This node is especially helpful for quick validation and exploratory inspection.
Scorer: The final node, Scorer, evaluates the predictive performance of the model. It compares the predicted labels against the true labels and outputs key performance metrics, including accuracy, precision, recall, F1 score, Cohen’s Kappa. These metrics provide a comprehensive view of how well the ViT model performs and whether it's suitable for deployment.
ViT Classification Learner
The central part of this workflow is the ViT Classification Learner node, which allows the tuning of transformer models to be applied to the specific task of image classification in the KNIME workflow. The node introduces advanced deep learning into the visual workflow, providing a powerful interface for model selection, training, and optimisation. The node works by dividing each image into small patches of uniform size and applying self-attention mechanisms to identify local and global relationships inherent in the image. The user can choose between different architectural variants, each suited to applications:
- Vision Transformer (ViT): the default ViT architecture offers excellent performance in generic image classification benchmarks. It works best with appropriately sized datasets and achieves excellent baseline results for most domains (Maurício et al., 2023).
- Swin Transformer: this model offers window-shifted attention and hierarchical feature maps, which are more efficient and effective for processing high-resolution images or complex visual patterns.
- Pyramid Transformer: designed with the goal of optimal multi-scale feature extraction, Pyramid Transformer works well on images where object sizes vary significantly. It has dynamic spatial attention, which is useful when precise details are required.
Each of these models has unique advantages depending on the complexity of the images, the size of the dataset, and the available computing resources.
How to configure the learner

You need to define:
- Image column: the specified input column where the image data resides.
- Label column: the target labels (i.e., the classes to be predicted).
- Number of epochs: how many times will the model process the dataset. Higher values help learning, but if too high, they can cause overfitting.
- Batch size: the number of images processed simultaneously. Larger batches can speed up training but are more expensive in terms of memory.
- Learning rate: adjusts the speed at which the model adjusts its weights. Lower rates favour stable learning, while higher rates can speed up the process but cause instability.
Once trained, the node produces an optimised transformer model, which can be applied to new images using the ViT Classification Predictor node.
ViT Classification Predictor
The ViT Classification Predictor node uses a fine-tuned Vision Transformer model, which has been trained by the ViT Classification Learner, on new image data. The task translates raw visual input into understandable predictions by categorizing each image into a learned category (e.g., "friendly" or "hostile"). In order to work, the node requires:
- A trained model from the ViT Classification Learner
- A dataset with the same image column that had been used to train
Once connected, the Predictor processes each image and outputs the predicted label. Additionally, it can generate probability estimates for each class, offering deeper insight into the model’s confidence in its predictions.
This node supports the deployment of all ViT-based architectures trained in KNIME, such as Vision Transformer, Swin Transformer, and Pyramid Transformer, so that your classification tasks can be readily deployed to production or further extended for evaluation.
Both nodes are ideal for bringing your image classification model to life, whether you're classifying medical image types, product defects, or, in our example, labelling scenes as "friendly" or "hostile." The ViT Classification Learner and Predictor nodes combined allow KNIME users to train, test, and deploy cutting-edge transformer-based models in a code-free workflow
Performance Analysis
An examination of performance measures for our case study of classifying images into “friendly” and “hostile” classes provides several key insights:
- Accuracy: The model was able to attain an overall accuracy of 0.933, meaning that nearly 93.3% of the images in the test dataset were accurately classified. This metric is a solid reflection of the performance of the ViT model on this specific dataset.
- Cohen's Kappa: Cohen's Kappa value of 0.867 indicates substantial agreement between the predictions of the model and the actual labels, higher than random chance agreement.
- Recall and Precision: Both "friendly" and "hostile" classes have high recall and precision values. This indicates the model's capability to correctly identify positive instances (recall) while simultaneously keeping the false positive identification rate low (precision).
The persuasive outcomes demonstrate the remarkable ability of the novel ViT nodes to solve difficult image classification issues in the KNIME platform.
The expanding potential of Transformer models in image analysis
Transformer models are opening new possibilities in the field of image analysis, demonstrating a major step forward compared to traditional CNNs.
In retail and consumer marketing he ViTs are being tested out for use in solutions ranging from object detection, visual sentiment analysis, to auto-detection of brands. For example, by inspecting social media user-generated content, the models can detect indirect hints for brand visibility, customer satisfaction, or visual leaning. This makes it possible for marketers to garner actionable insights at scale, leading to more contextual and targeted campaigns.
In e-commerce, ViTs enable more sophisticated recommendation engines through visual similarity comparison across products and interpreting the distinctions for style or category that a CNN would otherwise miss. In the medical domain, Vision Transformers are proving particularly successful. Unlike some vision models that rely on dense pixel-level information or hand-designed features, ViTs are especially well suited for understanding high-resolution, real medical imagery within their global field of view.
In industrial and manufacturing applications, ViTs are upending quality inspection processes. Traditional vision inspection equipment relies on rules-based or CNNs that have been fine-tuned for narrow defect classes. Vision Transformers, on the other hand, generalize well even in few-shot learning scenarios, where labelled examples are few and excel in the case of surface defect detection on textures such as fabric, metal, or electronics (Liu et al., 2021).
In autonomous applications and robotics, ViTs are being adopted for perception pipelines for autonomous cars, drones, and industrial robots. Understanding scenes, semantic segmentation, depth estimation, and pedestrian detection all benefit from the ability of the transformer architecture to understand global spatial relations. Current state-of-the-art models such as SegFormer (Xie et al., 2021) are enabling machines to traverse unstructured spaces with greater confidence and accuracy.
Vision Transformers constitute a new image analysis paradigm
The scalability, flexibility, and overall performance advantages make them increasingly valuable within real-world machine learning workflows.
These state-of-the-art models are made accessible for the first time to business analysts, data scientists, and subject matter experts alike through KNIME's new ViT nodes and intuitive visual interface. It offers greater than ever before the potential for experimentation with, deployment, and operationalization for real-world applications for transformer models.