As first published in Techopedia.
There is a lot of talk about data science these days, and how it affects essentially all types of businesses. Concerns are raised by management teams about the lack of data scientists, and promises are made left and right on how to simplify, scale, or automate this process.
Yet, little attention is paid to how the results can actually be put into production in a professional way.
Takeaway: Optimizing data science across the entire enterprise requires more than just cool tools for wrangling and analyzing data.
Obviously, we can simply hardcode a data science model or rent a pre-trained predictive model in the cloud, embed it into an application in-house and we are done. But that is not giving us the true value data science can provide: continuously adjusting to new requirements and data, applicable to new or variations of existing problems, and providing new insights that have profound impact on our business. (Read more on the Data Science job role here.)
In order to truly embed data science in our business, we need to start treating data science like any other business-critical technology and provide professional workflows to production using reliable, repeatable environments for both the creation and the productionization of data science.
Optimizing enterprize data science across multiple systems therefore requires more than just cool tools for wrangling and analyzing data.
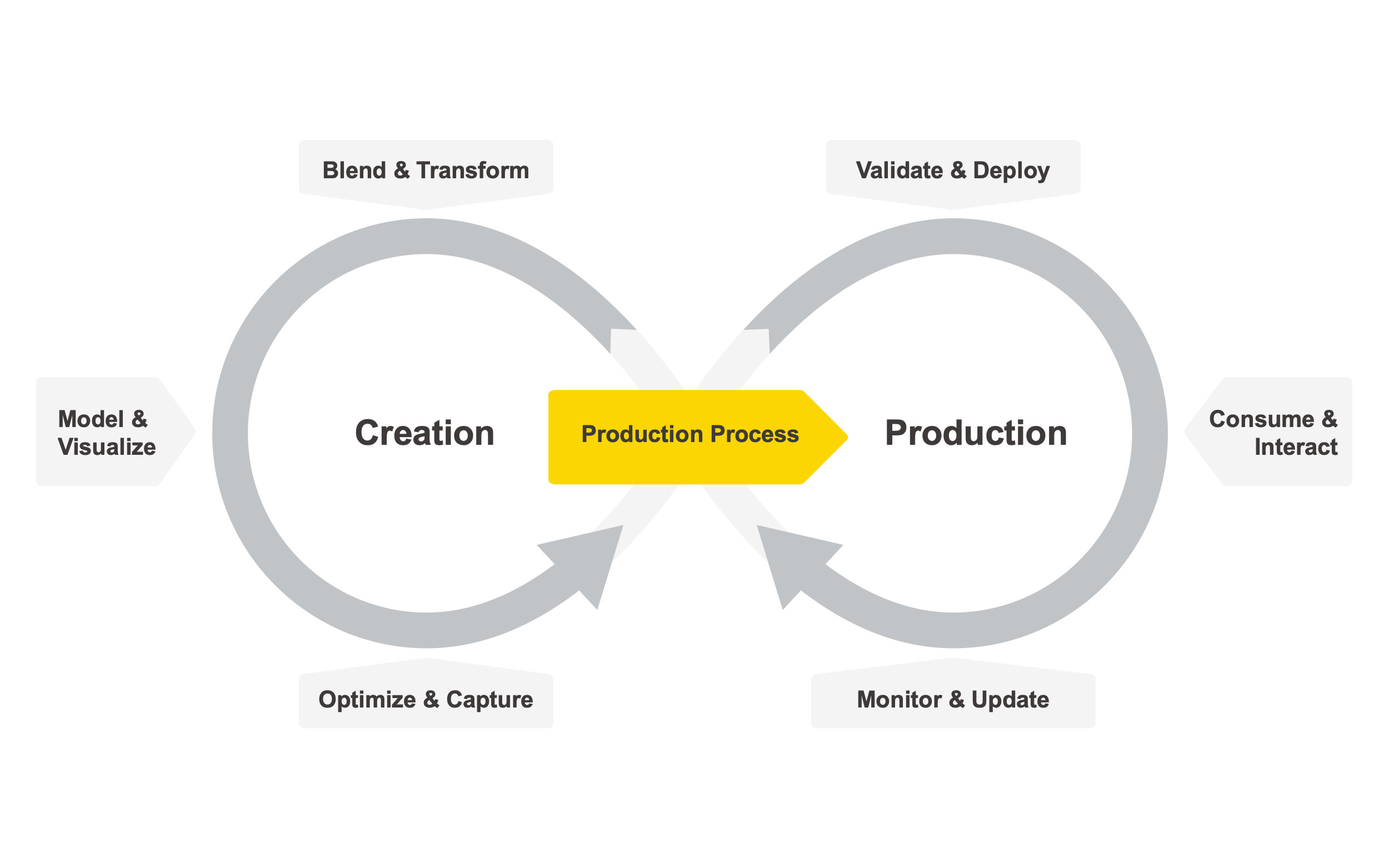
End to end data science: creation and productionization
Many of the processes we need to establish in order to support high quality, data science throughout an enterprise are similar to professional software development: solid design principles, release pipelines, and agile processes are required to ensure quality, sharing, and reproducibility while maintaining the ability to react quickly to new learning models.
Applying these concepts to data science enables continuous and fast delivery of new or updated data science applications and services as well as prompt incorporation of user feedback.
The typical four stages of end-to-end data science need to be tightly coupled and yet flexible enough to allow for such an agile delivery and feedback loop:
Data definition, accessing, and wrangling:
This is the classic domain of data architects and data engineers. Their focus lies on defining how and where to store data, providing repeatable ways to access old and new data, extracting and combining the right data to use for a particular project, and transforming the final data into the right format.
Parts of these activities can be addressed with a solid data warehouse strategy, but in reality, the hybrid nature of most organizations does not allow for such a static approach. Combining legacy data with in-house and cloud databases, accessing structured and unstructured data, enriching the data with other data sources (e.g. social media data, information available from online providers) continuously poses new challenges to keep projects up to date.
This is also the reason why most of this function needs to be part of the overall data science practice and cannot be owned solely by IT — the success of many data projects relies on quick adjustments to changes in data repositories and the availability of new data sources.
Automation here can help with learning how to integrate data and making some of the data wrangling easier, but ultimately, picking the right data and transforming them “the right way” is already a key ingredient for project success.
Data analysis and visualization:
This is where all those topical buzzwords come in: Artificial Intelligence (AI), Machine Learning (ML), Automation, plus all the “Deep” topics currently on everybody’s radar. However, statistical data analysis, standard visualization techniques, and all those other classic techniques must still be part of the analysis toolbox.
Ultimately, the goal remains the same: creating aggregations/visualizations, finding patterns, or extracting models that we can use to describe or diagnose our process or predict future events, so as to prescribe appropriate actions for the problem. The excitement for modern technologies has often led to people ignoring the weakness of applying black box techniques, but recently, increasing attention is being paid to the interpretability and reliability of these approaches.
The more sophisticated the method, the less likely it is that we can understand how the model reaches specific decisions and how statistically sound that decision is.
In all but the simplest cases, however, this stage of the data science productionizing process does not operate in isolation. Inspecting aggregations and visualizations will trigger requests of more insights that require other types of data, extracted patterns will demand different perspectives, and predictions will initially be mostly wrong until the expert has understood the reasons why the model is “off” and has fixed data issues, adjusted transformations, and explored other models and optimization criteria.
Here, a tight feedback loop to the data wrangling stage is critical — ideally, the analytics expert can, at least partially, change some of the data access and transformation directly. And, in an ideal world, of course, all this work is done in collaboration with other experts, building on their expertise instead of continuously reinventing the wheel.
Organizing the data science practice:
Having a team of experts work on projects is great. Ensuring that this team works well together and their results are put into production easily and reliably is the other half of the job of whoever owns “data science” in the organization — and that part is often still ignored.
How do we keep those experts happy? We should enable them to focus on what they do best:
Solving data wrangling or analysis problems using their favorite environment.
Instead of forcing and locking them all into a proprietary solution, an integrative data science environment allows different technologies to be combined and enables the experts to collaborate instead of compete. This, of course, makes managing that team even more of a challenge.
The data science practice leader needs to ensure that collaboration results in the reuse of existing expertise, that past knowledge is managed properly, and best practices are not a burden but really do make people’s lives easier. This is probably still the biggest gap in many data science toolkits. Requiring backwards compatibility beyond just a few minor releases, version control, and the ability to audit past analyses are essential to establishing a data science practice and evolving from the “one-shot solutions” that still prevail.
The final piece in this part of the puzzle is a consistent, repeatable path to deployment. Still too often, the results of the analysis need to be ported into another environment, causing lots of friction and delays, and adding yet another potential source of error.
Ideally, deploying data science results — via dashboards, data science services, or full-blown analytical applications — should be possible within the very same environment that was used to create the analysis in the first place.
Creating business value:
Why are we doing all of the above? In the end, it is all about turning the results into actual value. Surprisingly, however, this part is often decoupled from the previous stages. Turning around quickly to allow the business owner to inject domain knowledge and other feedback into the process, often as early as what type of data to ingest, is essential.
In an ideal world this can either directly affect the analytical service or application that was built (and, preferably, without having to wait weeks for the new setup to be put in place) or the data science team has already integrated interactivity into the analytical application, which allows the domain user’s expertise to be captured.
Being able to mix & match these two approaches allows the data science team to deliver an increasingly flexible application, perfectly adjusted to the business need. The similarity to agile development processes becomes even most obvious here:
The end user’s feedback needs to truly drive what is being developed and deployed.
Standardization, automation, or custom data science?
The last questions are:
Does every organization need the four personas above? Do we really need in-house expertise on every aspect of the above?
And the answer is most often:
Probably not.
The ideal data science productionizing environment provides the flexibility to mix & match. Maybe data ingestion only needs to be automated or defined just once with the help of outside consultants, while your in-house data science team provides business critical insights that need to be refined, updated and adjusted on a daily basis.
Or your business relies less on analytical insights and you are happy to trust automated or prepackaged ML but your data sources keep changing and growing continuously and your in-house data wrangling team needs full control over which data are going to be integrated and how.
Or you are just at the beginning of the data science journey and are focusing on getting your data in shape and creating standard reports. Still, investing in a platform that does cover the entire data science life cycle, when the time is ripe, sets the stage for future ambitions. And even if, right now, you are the data architect, wrangler, analyst, and user all-in-one person — preparing for the time when you add colleagues for more specialized aspects may be a wise move.
Data Science productionizing
Successfully creating and productionizing data science in the real world requires a comprehensive and collaborative end-to-end environment that allows everybody from the data wrangler to the business owner to work closely together and incorporate feedback easily and quickly across the entire data science lifecycle.
This is probably the most important message to all stakeholders.
Even though these roles have existed in organizations before, the real challenge is to find an integrative environment that allows everybody to contribute what they do and know best. That environment covers the entire cycle and at the same time allows to pick & choose: standard components here, a bit of automation there, and custom data science productionizing where you need it.
And finally, we need to be ready for the future. We need an open environment that allows us to add new data sources, formats, and analysis technologies to the mix quickly.
After all: do you know what kind of data you will want to digest in a few years? Do you know what tools will be available and what the newest trends will be?
I don’t.