
What do you do if you don't know something? Recently, our go-to solution often involves turning to ChatGPT. However, when it comes to seeking the most recent information, good old Google Search comes to the rescue as ChatGPT 3.5 (the free version) only has information up until September 2021. For instance, if you're curious about the recent Oscar winners in 2023, a quick Google search can lead you to a plethora of resources, like Wikipedia's web page, where you can see who won the Oscars.
Similarly, if you want to dive deep into information based on your organization, an AI-powered app using large language models is one of the most viable solutions available these days. You can train this app using internal documentation, your business-specific information, and other relevant data. This app can help you answer your queries with fitting responses that ChatGPT and even Google simply cannot do.
Customizing LLMs to build your AI-powered app provides unique advantages to your organization such as the ability to tailor it to your specific business needs, ensuring increased control over data privacy and security, and more. Customization ensures that the app aligns precisely with your objectives; for instance, an e-commerce platform provider could create a personalized recommendation system, elevating the overall customer shopping experience. Automating routine tasks, such as data entry or customer queries, frees up time for other important tasks thereby increasing efficiency. AI apps specific to your business can help you curate content based on your users.
In this article, we’ll offer an introduction to how LLMs can be customized and then integrated into interactive, dynamic dashboards or data apps for end users.
A quick intro to retrieval-augmented generation
Combining the traditional approach of searching for information (using retrieval models) with asking AI models like ChatGPT (using generative models) is referred to as retrieval-augmented generation. Retrieval-augmented generation (RAG) combines the strengths of both retrieval models and generative models.
Retrieval models are great for extracting relevant information from large datasets. However, they lack the nuanced ability to generate contextual appropriate responses. On the contrary, generative models excel at creating diverse and contextually rich content but need help with ensuring accuracy and relevance.
The hybrid RAG model strikes a balance. It can leverage the precision of retrieval models and integrate with a generative model for extracting relevant information and response generation. In simple terms, Retrieval is a search mechanism.
For example, it can be a keyword search, a vector search, and so on. Among these, one kind of search has been recently popular, namely, the semantic search with vector stores. This is because it is based on the technology of LLMs under the hood using a special kind of embeddings model. Along with its popularity, it has the ability to search semantically similar documents which, for example, a keyword search cannot do.
Semantic search with vector stores
An embedding model refers to a model that transforms words, phrases, or sentences into a numerical vector. This number captures the semantic relationship between words. This helps the algorithm to understand the contextual meaning of the text. That is, in contrast to other LLMs, the output of the embeddings model is not a text but is a vector that represents the semantics of this text. Let’s break this down. The embedding model is like a translator between sentences and numbers. These numbers are like a code also called a vector, that represents what the sentences mean.

To visualize what this means, consider a big board with points all over it. This is referred to as a vector space. Each point represents a different document, like articles, paragraphs, or sentences. The embedding model acts as a guide and places each document on the board. This process is not at random, if two documents are similar in meaning then they are placed close to each other. If you have a good guide, that is a good embedding model, it will organize all the documents such that similar documents are close to one another on the board.
In the example below, inside the small black oval, the document about the German Bundesliga is placed closer to the soccer World Cup document since they are similar. If we have a new question or document, the embedding model turns it into a point. Then to find other similar documents or to perform a semantic search, we can just look for the nearest neighbors, which are the documents that are closest to this new point on the board. The embedding model helps us organize information in a way that makes it easy to find things that are similar in meaning.
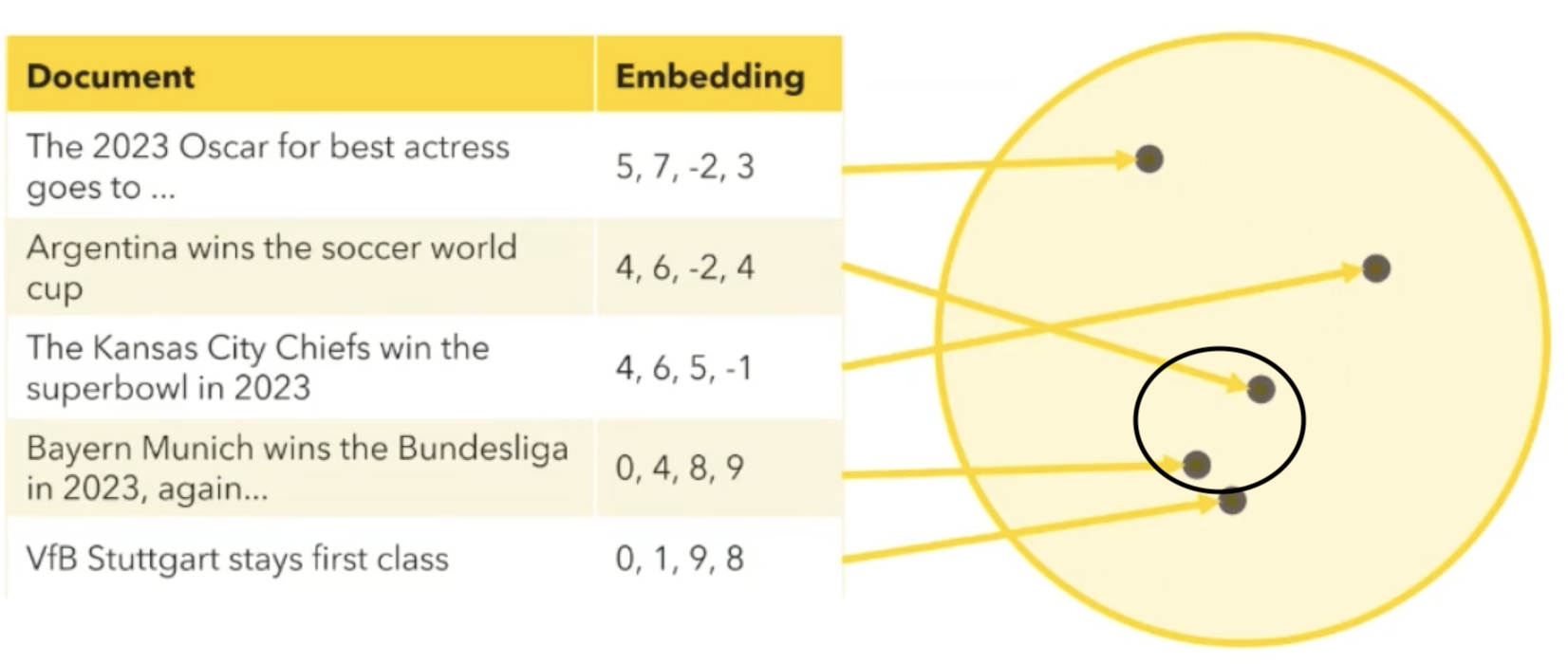
To perform RAG with an AI we start by searching our big board, also referred to as a vector store, with multiple points for semantically similar documents. We then combine these with our new document, allowing the AI to answer based on the context retrieved from the board and provide an informed response to the user. For example, consider the new document to be about “The 2023 Oscar for best picture goes to…”. The model would use all the information above and place this new document closer to other semantically similar documents. In this case, it would be placed near the document “The 2023 Oscar for best actress goes to…”.
Using RAG is a convenient way to customize LLMs instead of training an LLM from scratch. This is because it requires massive computational demands which is something that only the likes of AWS, OpenAI, and Google can afford to do.
Surface the new model via a KNIME Data App
Retrieval augmented generation (RAG) is a way to expose large language models to up-to-date information. This can provide additional context for an LLM to use this new content to generate informed output. This is the low-code and no-code approach to customizing a model.
For example, let's look at the workflow below that shows how to create a vector store from Wikipedia articles, query the vector store using the Vector Store Retriever to retrieve similar documents, and perform RAG using similar documents as context.
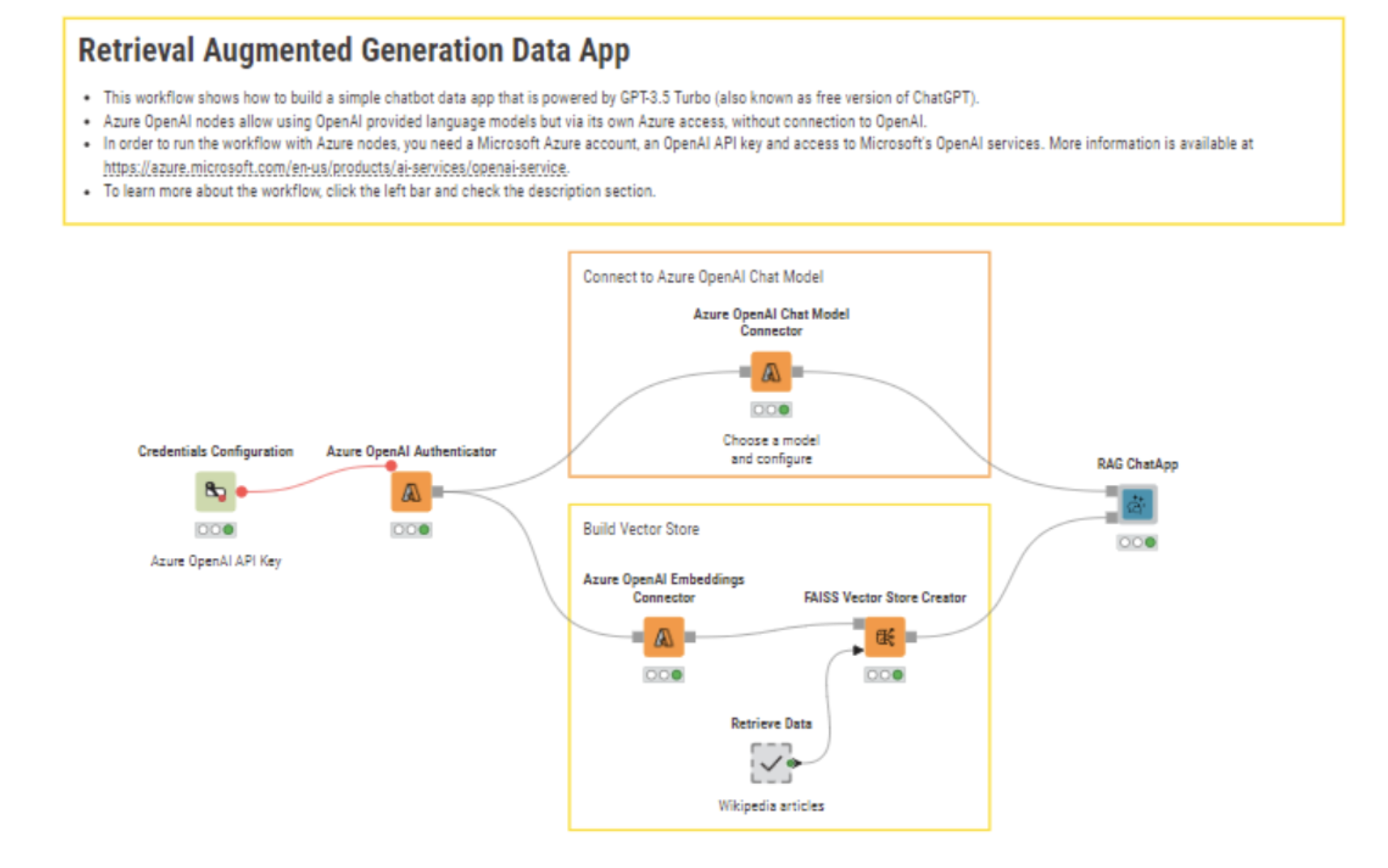
We will use the KNIME AI extension to build this data app. The nodes in this extension can connect to and prompt large language models (LLMs), chat, and embedding models provided by OpenAI, Azure Open AI Service, Hugging Face Hub, and GPT4ALL. This extension also has nodes for building and querying the vector stores Chroma and FAISS, as well as nodes for combining multiple vector stores and LLMs into agents that can dynamically decide which vector store to query for information given the user prompt.
Disclaimer: If you're new to the KNIME Analytics Platform, there’s no better starting point than downloading the latest software version- it’s open source and free of charge.
In this workflow, we first connect to the Azure OpenAI Embeddings Connector node and use the FAISS Vector Store Creator node to create a new vector store. We then connect this to our RAG ChatApp component. A component is a reusable and customizable building block that encapsulates a set of interconnected nodes. They have their own configuration dialog and custom interactive composite views. In this component, we will retrieve the most similar documents to the prompt made by the user using the Vector Store Retriever node and use the system message configuration to provide instructions for the model to behave in a certain way.
Then, we perform some prompt engineering. Prompt engineering, in this case, means we instruct and push the model to use the provided context to answer questions. We also hide all the retrieved documents from the user when providing a final output to create a nice chat experience. Finally, change our prompt to “Who won the academic award for best actress in 2023?” instead of 2021 since our context provides more recent information.
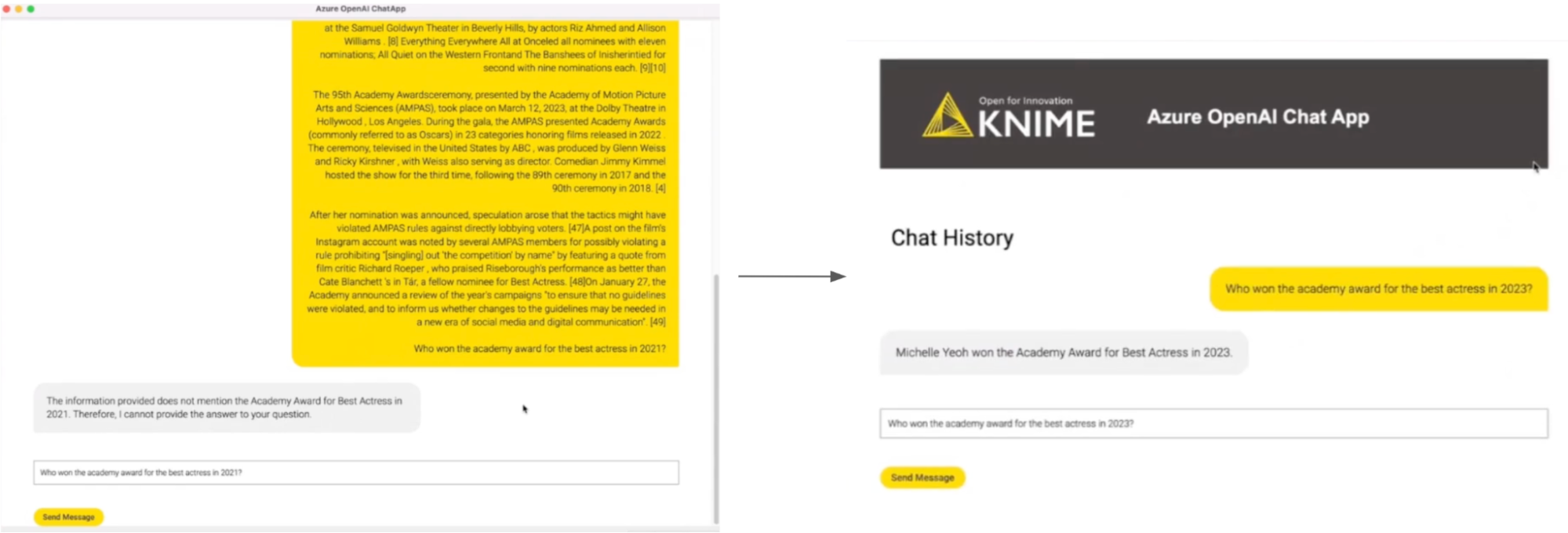
The above shows how some prompt engineering can transform the results into a concise and correct answer. This example uses information on the Oscars, but you can customize it to your needs by using news articles, internal documents, and so on.
Disclaimer: It is important to note that the data given to the data app is shared with Azure OpenAI (or whichever LLM provider is used). Internal documents should not be used as input unless approved by the organization that owns the documents.
Craft your personalized AI-powered data apps
Whether you're a seasoned data science expert or just starting your journey, this blog guides you in creating personalized AI applications. Learn to blend your data with large language models, tap into OpenAI's LLMs, utilize vector stores, and execute retrieval augmented generation—all through an easy-to-use, low-code/no-code interface. Elevate your AI journey with tailored solutions.
Browse through the AI Extension Example Workflows space which offers a curated collection of KNIME workflows, demonstrating practical applications in large language models, chat models, vector stores, and agents. It serves as a resource for understanding how to effectively utilize various AI capabilities within the KNIME environment for various tasks.