
In this blog series we’ll be experimenting with the most interesting blends of data and tools. Whether it’s mixing traditional sources with modern data lakes, open-source devops on the cloud with protected internal legacy tools, SQL with noSQL, web-wisdom-of-the-crowd with in-house handwritten notes, or IoT sensor data with idle chatting, we’re curious to find out: will they blend? Want to find out what happens when IBM Watson meets Google News, Hadoop Hive meets Excel, R meets Python, or MS Word meets MongoDB? Follow us here and send us your ideas for the next data blending challenge you’d like to see at willtheyblend@knime.com.
Today: Chinese meets English meets Thai meets German meets Italian meets Arabic meets Farsi meets Russian. Around the world in eight languages
Co-authors: Anna Martin and Mallika Bose
The Challenge
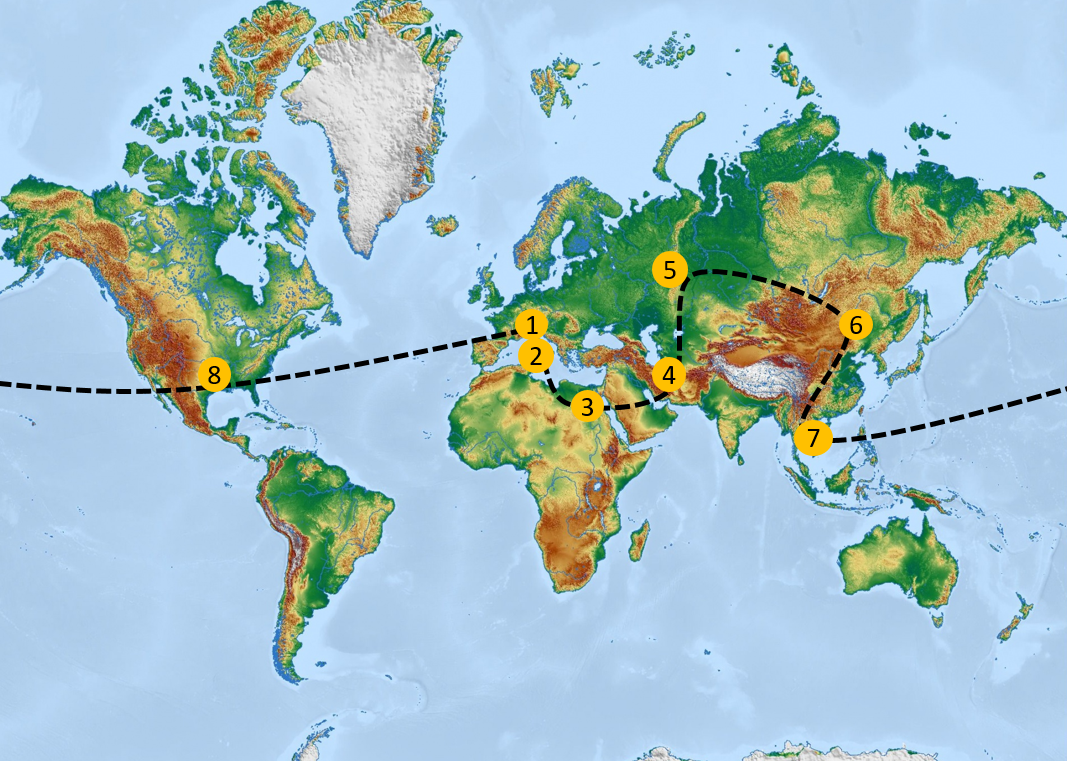
No doubt you are familiar with the adventure novel “Around the World in 80 Days” in which British gentleman Phileas Fogg makes a bet that he can circumnavigate the world in 80 days. Today we will be attempting a similar journey. However, ours is unlikely to be quite as adventurous as the one Phileas made. We won’t be riding Elephants across the Indian mainland, nor rescuing our travel companion from the circus. And we certainly won’t be getting attacked by Native American Sioux warriors!
Our adventure will begin from our offices on the Lake of Constance in Germany. From there we will travel down to Italy, stopping briefly to see the Coliseum. Then across the Mediterranean to see the Pyramids of Egypt and on through the Middle East to the ancient city of Persepolis. After a detour via Russia to see the Red Square in Moscow, our next stop will be the serene beaches of Thailand for a short break before we head off to walk the Great Wall of China (or at least part of it). On the way home, we will stop in and say hello to our colleagues in the Texas office.
Like all good travelers, we want to stay up-to-date with the news the entire time. Our goal is to read the local newspapers … in the local language of course! This means reading news in German, Italian, Arabic, Farsi, Chinese, Russian, Thai, and lastly, English. Impossible you say? Well, we’ll see.
The real question is: will all those languages blend?
Topic. Blending news in different languages
Challenge. Will the Text Processing nodes support all the different encodings?
Access Mode. Text Processing nodes and RSS Feed Reader node
The Experiment
Retrieving News via RSS Feeds
To get the RSS news feeds, we used the RSS Feed Reader node. The RSS Feed Reader node connects to the RSS Feed URL, downloads the feed articles, parses them with the help of a tokenizer, and saves them in a document type column at the output port.
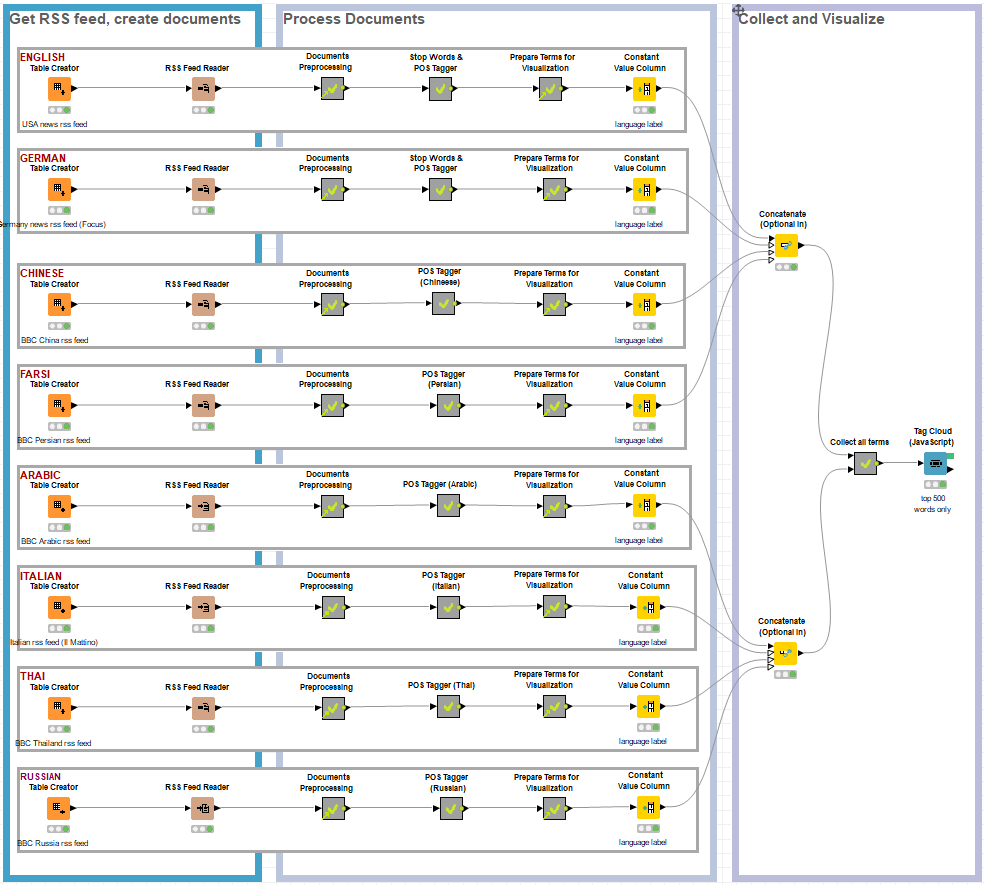
The workflow is available on the KNIME Hub The workflow comes in a folder containing two metanode templates necessary to the workflow execution.
It is important to notice that the text parsing operation performed by the RSS Feed Reader node is language dependent. A few language specific tokenizers are embedded into the node, such as for English, Spanish, German, and Chinese. However, for most of the languages, no specific tokenizer is available in the RSS Feed Reader node, nor in the other Text Processing nodes. In these cases, the two basic “Open NLP Simple Tokenizer” and “Open NLP Whitespace Tokenizer” might do.
Then, for each language, a Table Creator node with URLs of the local news, is fed to the RSS Feed Reader node. You can see the different language branches in the final workflow in Figure 1.
Document Pre-Processing
Document pre-processing mainly involves clean-up tasks such as: keep “Document” column only, remove all numbers, and erase punctuation signs.
Since those operations are language independent, the same metanode can be used for all languages. Not only eight replicas of the same metanode, but eight links to one single metanode template!
Note. The adoption of one metanode template makes maintenance much easier than using eight replicas.
To create a metanode template, just right-click the metanode in the workflow and in the context menu select “Metanode” → “Save as Template”, then select the folder destination in the KNIME Explorer panel, and click “OK”. The metanode will be saved as a template and the current metanode in the workflow will be transformed into a link to that template. Now, just drag and drop the metanode template into the workflow editor to create a new link to that metanode.
Each time the metanode template is changed, you have the chance to automatically update the currently linked metanode with the new content. Maintenance becomes much easier!
All metanodes named “Documents Preprocessing” in the final workflow are just links to the one and only metanode template, named “Documents Preprocessing”. You can see that from the green arrow in the lower left corner of the metanode icon.
This link to a metanode template feature was made available in KNIME Analytics Platform version 3.4.
POS Tagging
Part of Speech (POS) tagging is the detection of the grammar role of each word in the text (noun, verb, adverb, adjective, and so on). The second metanode in each branch of the final workflow is named “POS Tagger”. This metanode includes a node for stop word filtering, one or more nodes for POS tagging, and a Tag Filter node. All operations are language dependent, since both match words in the text against words in one or more dictionaries. For this reason, each POS Tagger metanode has been customized to work with the branch-specific language.
The Stop Word Filter node includes built-in stop word dictionaries for English, French, Spanish, Italian, Russian, and a few other languages. For these languages, we can then select the appropriate built-in dictionary. For the remaining languages (or if we are not satisfied with the current built-in list), we need to provide an external file containing the list of stop words we would like to eliminate. This was the case for Farsi, Arabic, Russian, and Thai.
Different nodes implement this operation. The POS Tagger node, for example, implements a POS schema for the English language. The Stanford Tagger node implements a POS Tagger for English and other languages such as German. Different languages use different POS models. For example, the Stanford Tagger for the German language relies on the STTS schema (Stuttgart-Tübingen-TagSet).
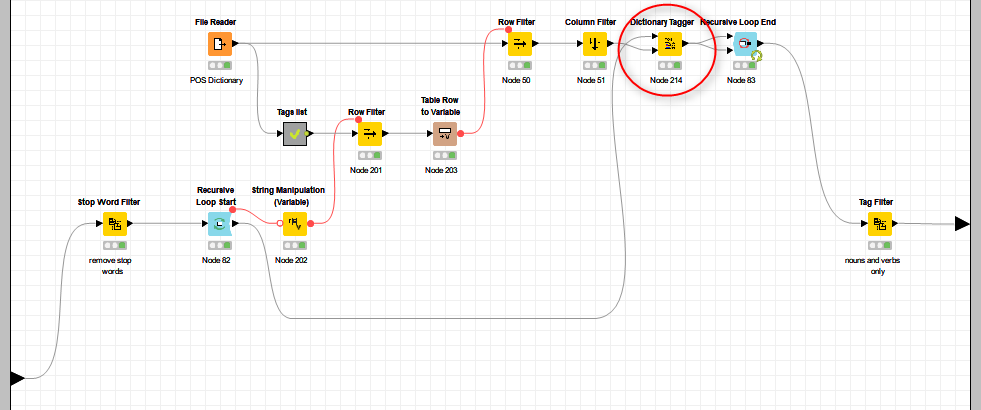
There was no POS Tagger for most of the languages considered in this blog post. In these cases, we created our own custom POS Tagger metanode. First, we retrieved a POS dictionary file for the language of interest, with word-POS-tag pairs, associating words to their grammar role tag. Finding such a dictionary is not always easy however, linguistic departments of local universities may offer some resources. Once we had a POS dictionary file, we associated the words with their specific POS tag using a Dictionary Tagger node. We began with nouns (NN), followed by adjectives (JJ), then verbs (VB), and so on. Thus, one of the possible implementations requires looping on all lists of words (all verbs, all nouns, and so on), and tagging the words in the text accordingly. Since previous tags must not be forgotten, a recursive loop is required here (Figure 2).
Note. The recursive loop enables looping on the data set for a fixed number of times, or when an end condition is met. Most importantly it has memory, meaning, the output dataset of the current iteration is passed back to be the starting dataset of the next iteration.
Please note, that proper POS tagging is a more complicated process than simply assigning tags from a list of words. The introduction of grammar rules together with the list of words in the POS dictionary would produce a more accurate result than what was implemented in this workflow. The basic tagging implemented here might however be useful, even if it is not entirely accurate. The quality of this basic POS tagging operation highly depends on the quality and the number of entries in the POS dictionary.
Of all tagged words, we only kept nouns and verbs using a Tag Filter node.
Note. The Tag Filter node is also language dependent, since different languages might use different POS schemas. For German, for example, the STTS schema (Stuttgart-Tübingen-TagSet) is used, instead of the POS schema used for English.
With this node, we conclude the language dependent part of our analysis.
Representation of Words and Frequencies in the Word Cloud
The next metanode, named “Prepare Terms for Visualization”, extracts all words from the documents and calculates their relative frequencies using a Bag of Words Creator node and a Tag Filter node. Relative frequencies of the same terms are summed up throughout the list of documents. For each language, the top 100 terms with highest cumulative relative frequency are extracted.
The “Prepare Terms for Visualization” metanode also performs language independent operations and can be abstracted into a metanode template. In the final workflow, each branch shows a link to the same metanode template.
The final 800 words from all eight languages, are colored by language and displayed in an interactive word cloud using a Tag Cloud (JavaScript) node.
The final workflow (Figure. 1) blends news in eight different languages: English, Italian, German, Chinese, Farsi, Arabic, Thai, and Russian. It is downloadable from the KNIME Hub. Notice that the workflow comes in a folder containing also the two metanode templates.
The Results
Whilst we did manage to read newspapers in each of the eight countries we visited, the news, the languages, the different writing, the great memories are all still mixed up in our head, in a very similar way to the word cloud in Figure 3.
The word cloud view resulting from the Tag Cloud (JavaScript) node is interactive. Words can be selected and then extracted from the output data table, filtering all rows with values in the column “Selected (JavaScript Tag Cloud)” = true.

We can conclude that while the different languages and the different writing do not really blend in the word cloud, the workflow we built can extract and process several different languages and can easily be extended to process additional languages, regardless of the encoding they require.
Languages do not blend, news feeds … yes they blend!
If you want to get a taste of a Babel mix of many different languages, we encourage you to attend the KNIME Spring Summit 2018, (Berlin, March 5 – 9). The Summit is where KNIME users and enthusiasts, including leading data scientists, from all over the world come to meet and network. Despite the diverse number of spoken languages, all training courses, sessions, and workshops will be held in English.
List of resources used for this blog post
Custom Stop Word Files
- Chinese https://gist.github.com/dreampuf/5548203
- Farsi https://github.com/kharazi/persian-stopwords/blob/master/persian
- Arabic https://github.com/mohataher/arabic-stop-words/blob/master/list.txt
- Thai https://github.com/stopwords-iso/stopwords-th/blob/master/stopwords-th.txt
- Russian: https://github.com/stopwords-iso/stopwords-ru/blob/master/stopwords-ru.txt
Custom POS Word Files
Acknowledgements
The creation of this blog post would not have been possible without the invaluable help of Mihály Medzihradszky and Björn Lohrmann, for the first inception of a workflow which could retrieve the news via RSS Feeder nodes. Also, Alfredo Roccato, for the implementation of text pre-processing and POS tagging, first for the Italian language and later for the other languages.
Coming Next …
If you enjoyed this, please share it generously and let us know your ideas for future blends.
We’re looking forward to the next challenge. For the next challenge we will tackle the virtual world. Will you be able to distinguish between reality and fiction? Will they blend?