

When I talk to young data science graduates, I often feel that they can train a deep learning model in 5 minutes, but have no idea where to go from there. After and before the model training and evaluation part, there is this big grey area where ideas are confused and directions unclear.
At the ODSC Europe conference 2017 in London, I gave a presentation and manned (or better womanned) the KNIME booth in the exhibition hall. One of the gadgets available at the KNIME booth was a series of fridge magnets mimicking the sequence of steps in a data science project. People could choose a magnet and take it back home. Guess what?
Most people chose "Analyze", some chose "Transform", but almost nobody chose "Deploy". I found this scary. Everybody trains models, but nobody makes them work in real life! I think the time has come for a review of the components of a complete data science project.
Data science processes often follow the same steps: data access, data exploration, data preparation, model training, model optimization, model performance evaluation, and finally model deployment. That has not changed with big data, deep learning, or with any of the new trends.
Setting data exploration aside, we can summarize the steps in a data analytics project with the classic CRISP-DM cycle (see the Wikipedia page for CRISP-DM Methodology). Projecting the circle onto a line, we could represent the process as follows.
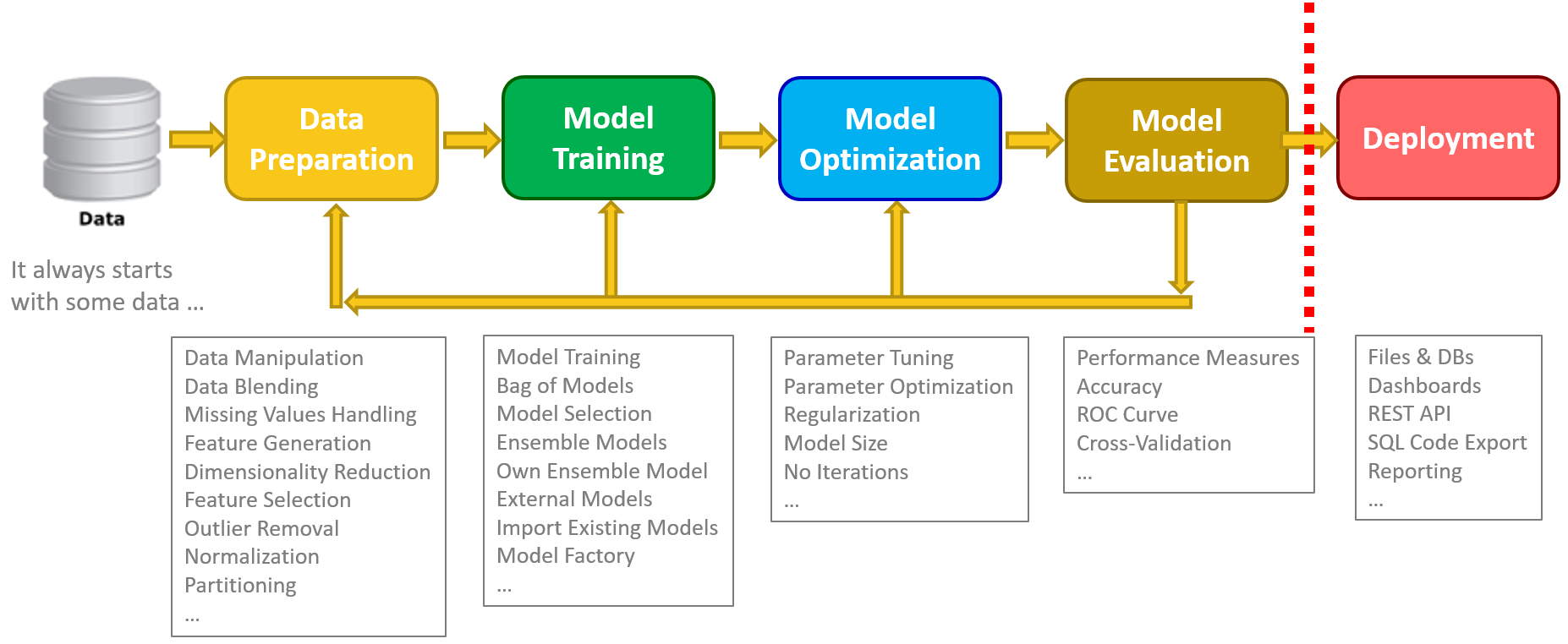
Each phase – data preparation, model training and evaluation, and model deployment – operates on its own data set. All these data sets need to be completely isolated from each other. The pollution of data sets across the data science assembly line is one of the most frequent mistakes in model production.
The data science journey always starts with some historical data lying around in a repository.
However large the original data set is, we often find that we could expand it with data from external sources. Here KNIME can help. It offers a number of connectors to web services as well as databases and other data sources. They are our secret weapon in this data blending phase.
After that the whole Data Preparation part starts: cleaning up data rows, removing outliers, imputing missing values, reducing dimensionality, generating better features, normalization, partitioning, and other transformations to make the dataset leaner and at the same time more informative. This is a crucial part of the project! Good data produce good models. Garbage data produce garbage models.
When we are satisfied with the quality of the data set, we can start the "Analyze" phase. Here the possible paths are many. We can select one particular model, train it, and evaluate it. Or we can train many models, evaluate them, and compare them to choose the best. Or, if we are competition averse, we can train many models and make them work together on the same problem. Those are ensemble models and the cooperation makes them more robust towards false predictions. We can use pre-packaged ensemble models or create our own. We can import pre-existing models, even created by other tools. We can train a model with an initial parameter set and then optimize it to get the best performance. And so on. There are plenty of options.
At any point of the cycle, if we are not satisfied with the final model performance, we can go back and change model(s), parameters, or data preparation techniques. The training of a model is an iterative process, where experience and domain knowledge plays a big role.
We have almost reached the end of our journey, i.e. the red line in the figure, which indicates the coming of age of our infant model: Deployment. This is usually a separate workflow, feeding live data into the model and storing or displaying the results in a database or on a dashboard. Here speed is often important, since most deployments happen on-line, while training might run off-line.
I hope this post made clear what the phases of a data science project are, what steps each phase consists of, and how important each step is. If you want to know more, below is a list of YouTube videos covering most of these steps in the data science process.
Stay up to date! Subscribe to our KNIME YouTube Channel https://www.youtube.com/user/KNIMETV