
KNIME as a gateway to computational social science and digital humanities
I discovered KNIME by chance when I started my PhD in 2014. This discovery changed the course of my PhD and my career. Well, who knows: perhaps I would have eventually learned how to do things like text processing, topic modelling and named entity extraction in R or Python. But with no previous programming experience, I did not feel ready to take the plunge into those platforms. KNIME gave me the opportunity to learn a new skill set while still having time to think and write about what the results actually meant in the context of media studies and social science, which was the subject of my PhD research.
KNIME is still my go-to tool for data analysis of all kinds, textual and otherwise. I use it not only to analyse contemporary text data from news and social media, but to analyse historical texts as well. In fact, I think the accessibility of KNIME makes it the perfect tool for scholars in the field knowns as the digital humanities, where computational methods are being applied to the study of history, literature and art.
Mining and mapping historical texts
My own experiments in the digital humanities have focussed on historical Australian newspapers that are freely accessible in an online database called Trove. I have developed methods to combine the thematic and geographic information contained in these historic texts so that I can map the relationships between words and places. This has been a very complex and challenging task, and I have used KNIME every step of the way.
First, I used KNIME to obtain the newspaper data from the Trove API. In the process, I created the Trove KnewsGetter workflow. I then used KNIME to clean the text, identify placenames and keywords, assign geographic coordinates, calculate the statistical associations between the words and places, and prepare the results for use in Google Earth and Google Maps.
The TroveKleaner: An experiment in OCR error correction
When I say that I used KNIME to ‘clean’ historical newspaper texts, I don’t just mean by stripping out punctuation and stopwords, although I did that as well. I also did my best to correct some of the many spelling errors that result from glitches in the optical character recognition (OCR) process through which the scanned texts on Trove have been converted. Some of the original texts in Trove are difficult to read even with the human eye, so it is no surprise that machines have struggled! The example below shows a scanned article next to the OCR-derived text, with the OCR errors shown in red.

I used some highly experimental methods to correct these OCR errors.
To correct ‘content words’ (that is, everything except for ‘stopwords’ like the or that), I extracted ‘topics’ from the texts using KNIME’s Topic Extractor (Parallel LDA) node and then used string-matching and term-frequency criteria to identify likely errors and their corrections. A high-level view of the steps I used to do this is shown below in Figure 2, while an example of the identified corrections can be seen in Figure 3.
To correct stopwords, I first identified common stopword errors (which conveniently clustered together in the extracted topics) and then analysed n-grams to work out which valid words appeared in the same grammatical contexts as the errors.
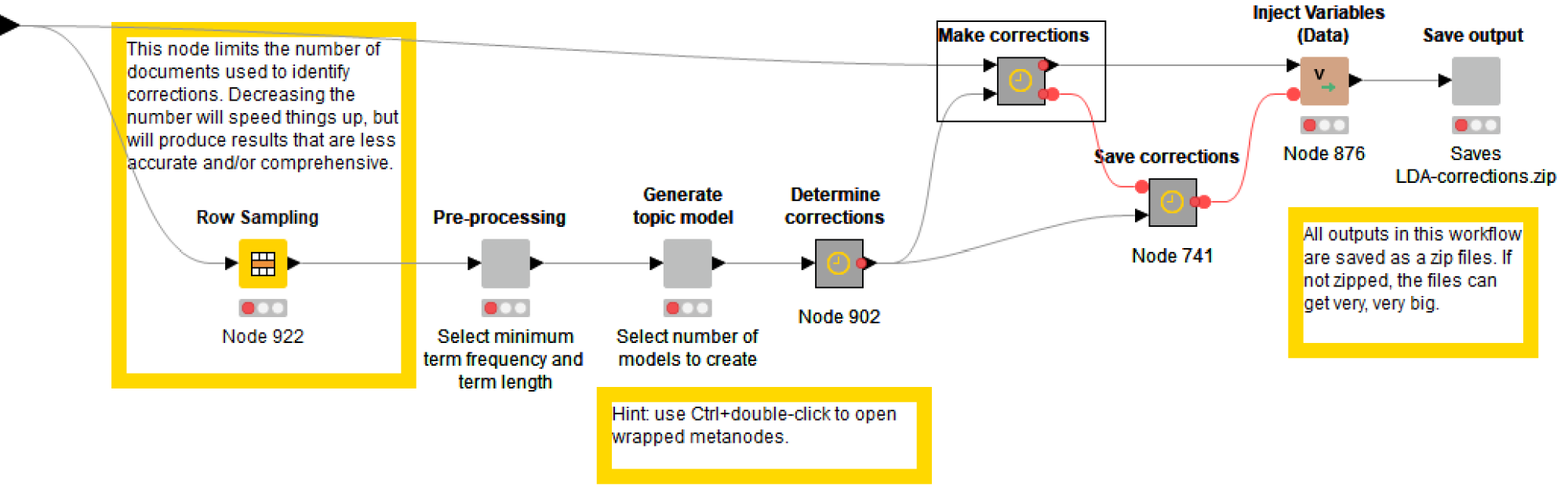
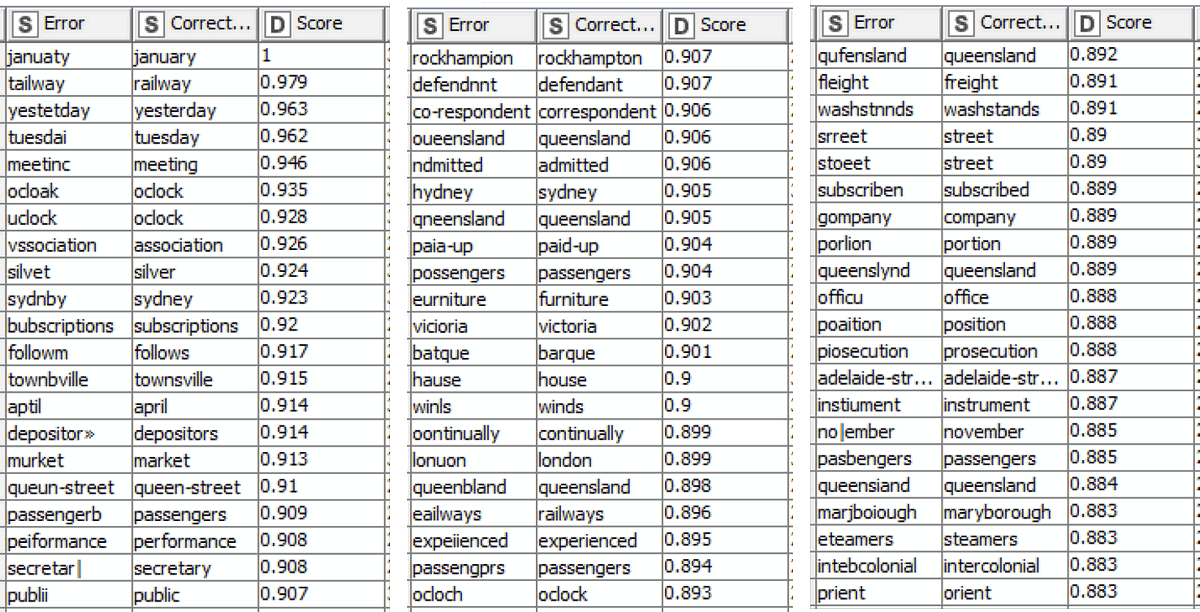
Neither of these methods was ever going to be perfect or comprehensive, but they worked well enough to make the experiment worthwhile. And well enough, I think, to make the methods worth sharing. So I cleaned up and annotated my workflow to produce the TroveKleaner. (I do my best to include a K in the name of all my KNIME workflows!) As shown in the ‘front panel’ view below, the TroveKleaner contains several separate components, which can be run in an iterative, choose-your-own-adventure fashion.
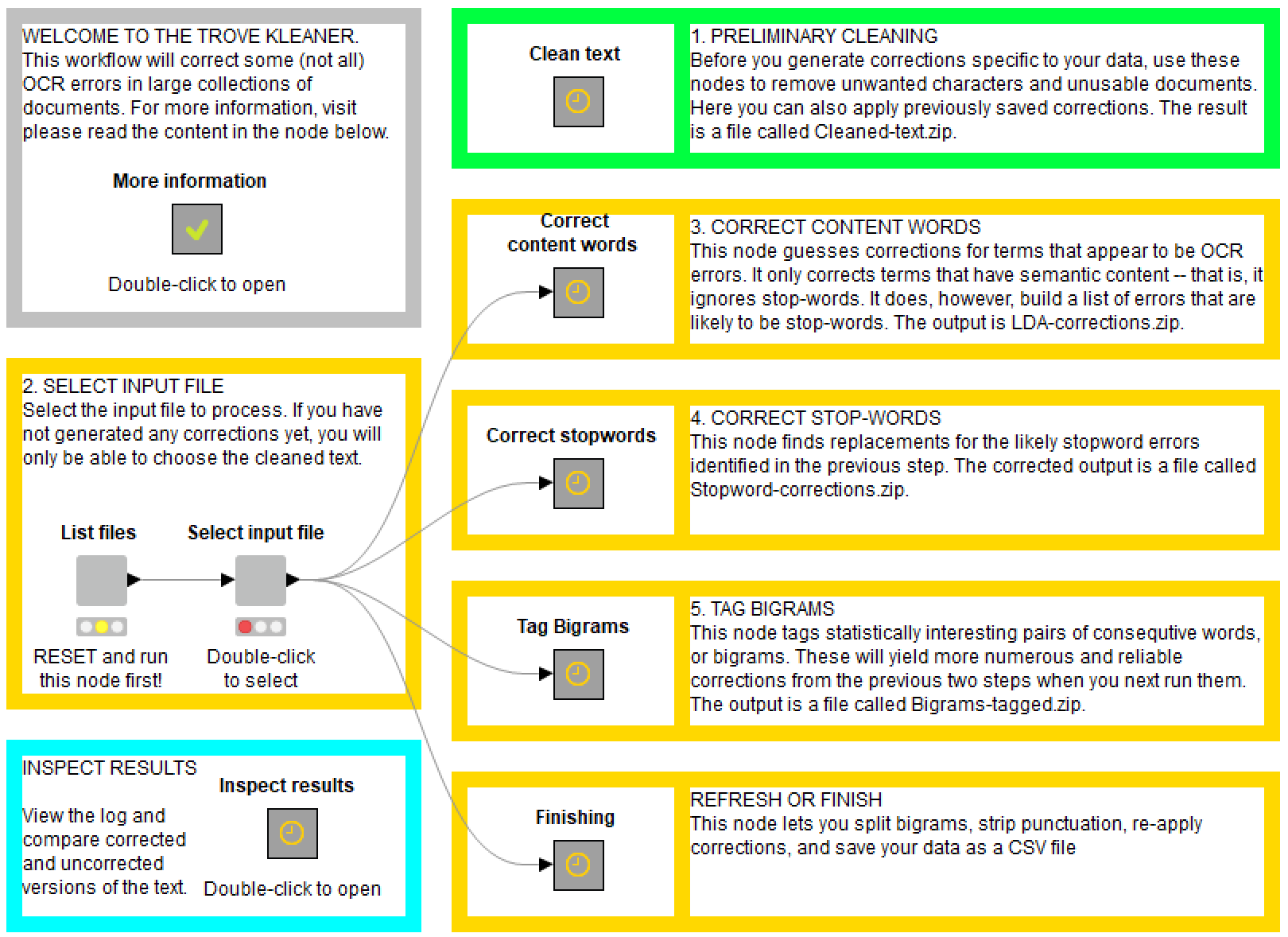
Of course, the TroveKleaner will not just work with texts from Trove. The texts could come from anywhere! The only requirement is that your texts number into the hundreds, and preferably thousands. The TroveKleaner draws on nothing except the data itself to identify corrections, and so relies upon the statistical weight of numerous ‘training’ examples in order to work effectively.
If you are interested in the TroveKleaner, you can learn more about it on my blog.
Sharing the TroveKleaner on the KNIME Hub
Like any good scholar working in digital humanities or computational social science, I originally made my workflows, including the TroveKleaner, available on GitHub. That’s where all useful code is shared, right? Perhaps. But KNIME workflows aren’t really code. They work like code, but they are made of something else: I call it kode, in honour of KNIME’s famous first letter. And let’s face it: GitHub was never designed to host kode. Sharing my workflows there has never felt quite right.
This is why I was delighted to learn about the KNIME Hub. Here, finally, is a repository designed especially for sharing kode. No more need for ‘commits’ or ‘pulls’ or clones or readme files! Just a seamless drag-and-drop operation executed from within KNIME Analytics Platform itself.
Originally, this post was supposed to be about how I shared the TroveKleaner on the KNIME Hub. But honestly, there’s hardly anything to write. It just worked, exactly like it is supposed to.
With a simple drag-and-drop, my workflow now has an online home where it can be easily found and installed by fellow KNIME users. Its page on the KNIME Hub includes the description, search tags, and links to my own blog that I entered into the workflow metadata from within KNIME.
Especially useful – and something I hadn’t even considered when I uploaded the workflow to GitHub – is that the KNIME Hub lists the extensions that must be installed for the TroveKleaner to work.
Note that one of these extensions, the fantastic collection of nodes from Palladian, is not in the usual repository of extensions but requires the user to add an additional source (as the authors now want to enforce a different license).
Indeed, the process was so easy that I also went ahead and uploaded my Trove KnewsGetter workflow to the KNIME Hub. With any luck, I will upload more workflows in the near future!