
Senior Director of the Marketing Innovation Center at Juniper Networks, Srinivas Attili, discusses navigating a "Forest of Tools and Islands of Information" to create the enterprise capability that delivers valuable business insight.
“Big-Data! What the heck does that mean?”
Often, organizations adopt tools and systems as per the emerging technology trends and their organic needs. This leads to a situation where a company’s technology landscape often resembles a forest of tools crowded in one place, however each tool is different from the next.
Information created by these diverse tools is often known only to a small group of people within the company and remains isolated from such pools created by various other systems. These unconnected islands of information need to be brought together, synthesized to derive insights that would not have been realized with the siloes of data.
“Big-Data! What the heck does that mean?” asked a colleague five years ago. Thus started my journey to unravel the emerging technology trends in the market and create the capability (Center of Excellence) that delivers valuable insights to business.
Setting up any new CoE will require thorough planning to build the four pillars needed for success. These are:
-
People
-
Process
-
Tools
-
Recognition
Well, what will we be solving?
Even before diving into setting up the CoE, we needed to define what business questions we would answer with this new capability. In fact this seemingly simple question is very hard to answer. And we ended up with the dreaded sentence “Show me what the data tells that I don’t know”. This is a trap; one should tactfully avoid this scenario and develop the use cases with a clear definition of what the success looks like.
1. The People
The biggest learning experience shows that not everyone needs to be a data scientist in a data science organization. One needs to assemble a team that consists of different talents that fulfill specific jobs. Based on my experience, I have divided the roles into the following categories:
Data Engineers:
These are people with a software engineering background. Data engineers build what we call a data pipe. Their primary responsibility is to develop and maintain the workflows that bring data into the data lake via ELT processes. In an enterprise environment, maintaining the data pipes, streams, and ELT workflows is a full time job especially when the data lake is mission critical for the organization’s business.
Data Scientists:
There are tons of excellent articles on the internet that go into the details of how to hire a data scientist. And with the current marketing hype around this role, everybody wants to become one. There are reams of literature about what should be the ideal skill set of a data scientist and which algorithms they should be aware of etc. While all of this is important, from the practical business application perspective, what’s needed is a person who understands the data first then identifies the right set of questions that need to be answered and applies the relevant statistical test or algorithms to the data and most importantly tells the story. The “Story Teller” part is often overlooked by many enthusiasts and industry experts, as well. From my experience interviewing several dozens of candidates for data scientist roles across the globe, there is always intense pressure on the person to know all the cool algorithms. However, 80% of such candidates was not able to articulate the story their analysis generated. In an enterprise environment, a data scientist needs to be an evangelist too.
Business Analysts:
This is a somewhat complimentary function and not every business needs to include business analysts in their data science organization. However there are several use cases where the analysts can answer the business question leveraging the models developed by the data scientists.
Complementary / Support roles:
Several other support roles are required to complete the team. System administrators in cases where the IT department doesn’t provide the solution, cloud architects to navigate the labyrinth of ever evolving cloud services landscape, scrum master or project manager to keep everyone’s sanity, etc.
To learn more about the various roles required in data science environment, I would recommend going through this excellent blog on KD Nuggets.
2. Tools! Tools!
This is everybody’s famous subject. Let’s have a Hadoop cluster, no no, let’s go to cloud, in-memory systems, what about H2O, tensor flow, Elk stack and the thousand other platforms out in the market. You will be bombarded with marketing information about various off the shelf tools, self-service analytics and do it all providers.
My boss once said, “I wish someone could give me a handbook on how to set up advanced analytics functions, instead I get bombarded with all sorts of flashy marketing material about yet another magic tool”.
Let’s face the reality, there is no one size fits all tool or platform that will magically solve your business problems. There are tools with several degrees of maturity and automation, however they are not going to be substitutes for the deep understanding of the business knowledge and your own company’s data. Every company does things differently and intimate knowledge about that is the primary requirement. Tools are secondary.
However, when you have to make a decision about the tools and platform, take into account the business use cases and decide on the platform that is most economical, can grow the capacity, and add additional modes of processing if necessary. You need to evaluate if the data ingestion is going to be all batch mode, steaming, or a hybrid of both. You need to consider how your end users are going to interact with the data. Do you need self-service BI tools, visual analysis & dashboards or high speed SQL or NoSQL databases to feed into your applications? I will delve into various architectural choices in a separate article.



3. Process
Setting up processes is an under-represented aspect of the data science organization.
Is a data science organization considered an operations or software development organization? Should we follow agile methodologies or traditional waterfall project management?
Finding answers to the above questions at the earliest possible time will save a lot of burnouts. Different companies may have set up their data science organizations with a specific charter. In my experience, the data science team is a hybrid of both operations and projects. Data pipe management and application reliability management are considered operations. Creating standard operating procedures (SOPs) is an important element for reliably managing these operations.
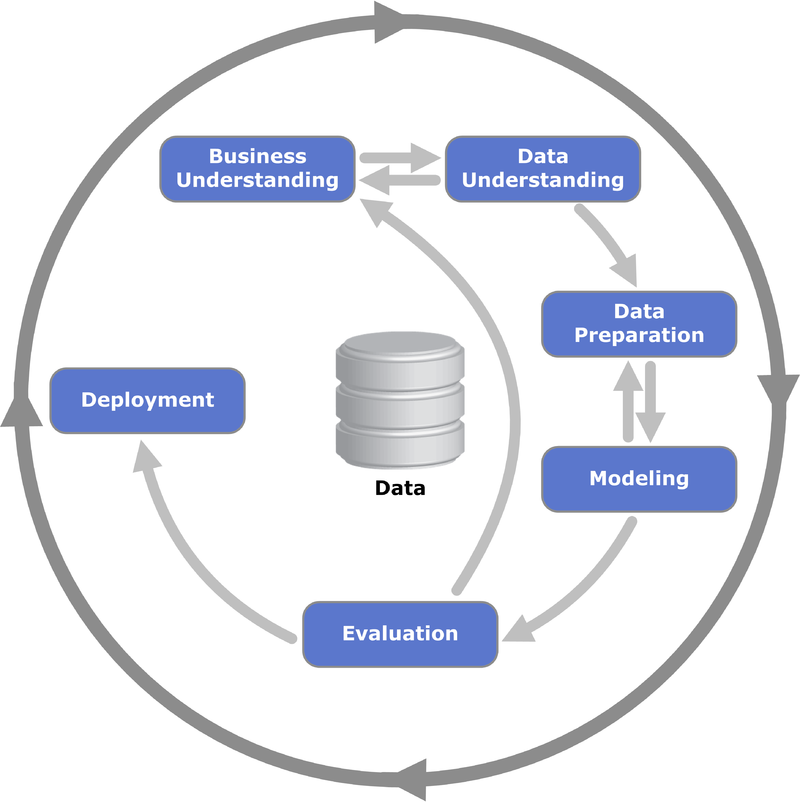
Model development and business use case analytics are driven by project management methodology. We first started with the traditional waterfall process following CRISP-DM methodology. Later we adopted scrum methodology and found it suitable for our requirements for analytics projects.
4. Recognition
Recognition needs to be an integral part of any organization’s culture. Especially the prestige associated with data science team and their role. It’s important to cultivate an environment of innovation and exploration in the team. One could encourage the team members to be evangelists for the data-driven decision making in the company. Apart from the formal recognition and awards that are available as per the HR guidelines, one can motivate the team to keep driving innovation.
My experience shows that everyone gets engaged when they are involved in higher order work. We run an innovation council that takes inspiration from Google’s 20% project time (read more about it in the book “Work Rules by Laszlo Bock”). We run mini projects to create patentable IP, encourage team members to contribute to industry forums and present papers. And we work with top universities to drive some fascinating research.
Continuing the Data Science Journey
Creating a data science organization from scratch is an exciting and arduous task. With information overload on the latest and greatest innovations, it is always difficult to understand where to start. As per the oft repeated crawl-walk-run euphemism, it is important to get the basics right and then move onto more complex and advanced technology adoption. This is a continuing journey, an exciting one at that.
Juniper Networks gave a talk at the KNIME Fall Summit 2018, November 6-9, 2018 in Austin, Texas, US. Explore the slides presented by Shalini Subramanian on “Enterprise Scale Data Blending” and Owen Watson on "REST API: Workflow Integration with Python".