
Here we are, 10 years later! It has been an incredible journey, both challenging and rewarding at the same time. Starting from an embryo idea in 2006, to make data analytics available and affordable to every data scientist in the world, we have embarked on this adventure with undefined expectations about the future. As you can often judge a book from its incipit, those initial steps gave some early indications about what the KNIME platform and the KNIME company would bring.
KNIME philosophy
KNIME’s philosophy has always been to build an open platform for data science people. The first interpretation of such thought was to create an affordable and easy to use tool. Of course, in order to be of any use to a data scientist, such a tool would also have to cover as much as possible of machine learning, statistics, ETL, data blending, and data visualization. Along the same lines, it must be able to import data from as many data sources as possible, and - why not? - from as many different data science tools as possible. Later on, our open platform philosophy progressed into the generation of a team collaboration tool. Times have changed and a single isolated data scientist is not enough anymore; teams of data scientists and data analysts working together are needed. And of course, we couldn’t neglect speed and agile prototyping. So many challenges, all to be satisfied in a quick and elegant way!
This constant attention to the needs of data science teams around the world combined with the courage to embrace openness and integration has made KNIME one of the most innovative companies in the field of data science over the last 10 years. Today, we are proud to confirm that the choice of building an open platform has led to a completely new way of managing data analytics, a way that is friendly, approachable, easy, extensive, powerful, inclusive, affordable, collaborative, and graphical. A way that many have tried to copy, but never really equaled. This might also be because KNIME is primarily motivated by passion and science rather than money and revenues.
Of course, this KNIME philosophy was not shaped in one day. It has taken 10 years to develop and formalize it to the current point. But all the ingredients were already present right at the beginning. This blog post takes you on this 10-year journey.
Graphical User Interface
The first concept in the minds and documents of the KNIME development team was to provide yet another script, easy to learn, consistent, back-compatible, memory-savvy, fast, and scalable. A few well implemented libraries could suffice … or maybe not. Maybe a graphical interface could work better. Indeed, if well done, a graphical interface would certainly be easier to understand and to learn. It would also be easier to document, since it could allow for inline documentation. So, it was decided. A graphical interface it would be.
Since programmers believe they can do anything and because not that much professional help was available (buyable) at the time, the first graphical interface for KNIME 1.0, shown in Figure 1, was … unappealing, un-colorful, and un-describing. But a few key concepts have survived: the node pipeline, the node status as a traffic light, the connections. We were on the right track! Beauty and versatility would come with time!
Figure 1. KNIME Analytics Platform v1.0 back in 2006
(click on the image to see it in full size)
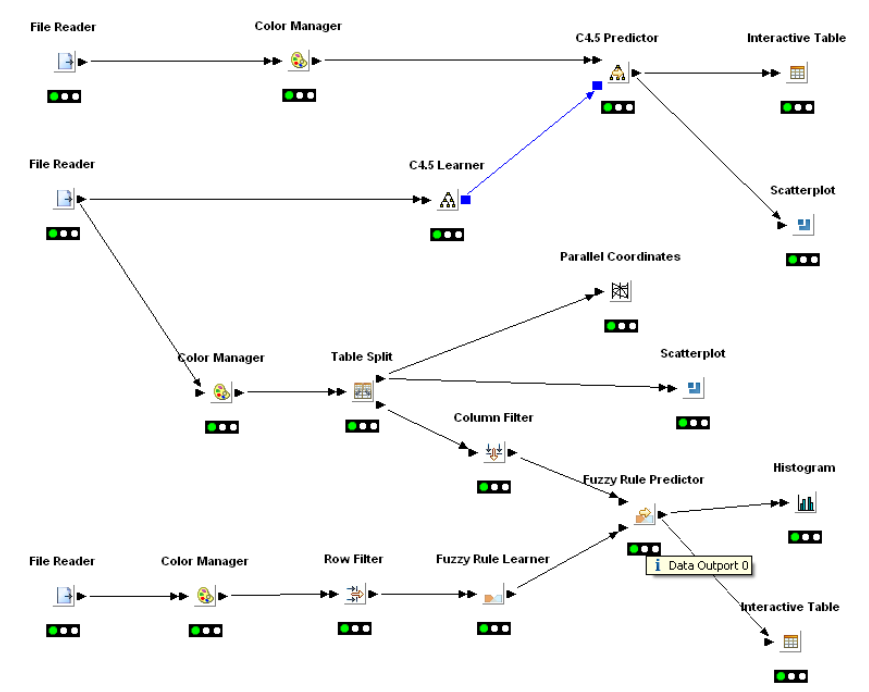
Figure 2. KNIME Analytics Platform v3.2 now in 2016
(click on the image to see it in full size)
The graphical interface has evolved in the last decade to reach what you now see in KNIME Analytics Platform 3.2 (shown Figure 2) Nice, huh? Well, it took just time and … some professional help to get there!
The new node icons with their modern colorful look were first introduced in version 2.0, then improved in version 3.0. Annotations and node comments were added in version 2.3. Bendable connections have been there practically from the start - they were introduced in version 1.6. Talking about node connections, I can give you a secret insight into the upcoming version 3.3, in which curved connections will also be possible.
In version 3.0 the logo was also updated, moving from the shaded triangle using the arrow for self-reference to a series of triangles on multiple levels. We like to think of it as a fractal logo, where deeper observation leads to new smaller triangles, showing how a deeper investigation into a data science problem leads to other data science problems on a different detail level.
The Open Source Choice and the KNIME Community
Open source was another natural choice from the beginning. And we remain committed to that original path!
We did not choose open source purely because of price, as an enticing marketing strategy, but wanted to build a community of capable, professional, and collaborative data scientists. A healthy community helps the software advance with development, testing, support, documentation, and examples. A healthy community grows faster and more easily around an open source tool and, let's face it, lots of innovation comes to KNIME from those community extensions. No single, proprietary company get do that.
Over these last 10 years, we have received tons of help and support from the community. In addition to the current more than two million lines of code, another more than half million are contributed by the community, often in the form of entire free extensions. Another part of the community has been the backbone of the KNIME Forum. A large number of KNIME developers and data scientists have grown professionally following the advice and explanations of a growing number of dedicated advocates in the KNIME Forum.
We would like to take the chance here to thank all code contributors and all forum supporters who were active at different times over the past 10 years. Thanks to your enthusiasm and competence we never regretted the open source choice. You have helped us shape a great tool and educate a new generation of data scientists!
Extensive Coverage of Analytics
Quoting an anonymous source, the open source philosophy has made KNIME a small company with a huge R&D department!
The community has contributed to the code not only in terms of quantity but also in terms of quality. Many of the cutting edge nodes for data mining, parallel processing, advanced integration, and more have been provided by the KNIME development team as well as by the best higher education institutions and R&D departments around the world.
More than 1500 dedicated nodes, as of now, extensively cover machine learning, data manipulation, data blending, big data, statistics, data access, data visualization, text processing, and all of your needs for data analytics, in general. They also cover cutting edge algorithms, such as deep learning, ensemble methods, streaming and parallelization, LDA in text processing, gradient boosted algorithms, and very likely more to come in the next years. This could not have been possible without the help of entire university groups and R&D departments.
The Integration Feature. Not just Data Blending, but also Tool Blending
Data blending is the minimum required feature in a data science tool. Any data science tool should have it and the KNIME development team has dedicated a big part of these past 10 years to integrate a large number of different data formats and to include a number of nodes to blend data from different sources.
KNIME development has not stopped here. We took the blending/integration approach to a completely new level. After data sources, we also integrated a number of data science tools into the KNIME platform. Java was the first one (v1.1), then came R (v2.2), then Python (v2.12), Weka, JSON, XML, Spark, etc …
Today, KNIME Analytics Platform is the platform that integrates the most external tools without any fear of competition, but in the spirit of collaboration.
Collaboration
Right, collaboration! In modern data science labs we find a bit of everything: the R user, the KNIME user, the big-data expert, the business analyst, the historical Excel documents, and more. It is normal nowadays and we need to accept that. Anyone thinking that a data science lab can work with only one tool and a few homogenous experts, should go back to the 90s.
The integration feature described above, on tools and data sources, harmonizes all those different skills, while the KNIME expert and data science director keeps the control of the investigation.
However, in order to enhance collaboration among different roles in the data science lab, a few additional commercial products have also been developed in the past years. These commercial products address the problem of sharing knowledge, data, solutions, and workflows in a central repository, in the shape of templates, productive solutions, or just temporary prototypes.
KNIME Server saw the light in 2010, offering remote execution and a central repository. It has grown since then, moving from a Glassfish to a Tomcat based infrastructure. It has integrated scheduling, versioning, and rollover. The WebPortal, the server graphical output on a web browser, has been introduced around 2012 and graphically remodeled in 2015. Calls to internal and external workflows, Quickform and Javascript based nodes, exposing workflows as REST services, and cloud-based versions now make it a very reliable tool for DWH, guided analytics, and workflow orchestration. KNIME Server has become an invaluable help in the organization of the daily work of an enterprise data science lab.
Speed and Scalability
Besides the extensive coverage of data science requirements, KNIME has received great appreciation for speed in many evaluation reports (Gartner 2014, 2015, 2016; Rexer Analytics 2013, 2014). This is actually a nice side effect of a well-designed, elegant, and thought-through software architecture.
KNIME Analytics Platform makes best use of the available hardware by using a smart memory handling algorithm and also by parallelizing computation when possible. In fact, starting from KNIME Analytics Platform 3.1, a workflow can be run in streaming mode using a streaming executor. This significantly reduces I/O and hence further increases throughput. As of now, most of the relevant nodes are streamable and can be executed in streaming mode.
However, if scalability can only be reached via a big data platform, such as Hadoop or Spark, you can always draw on the KNIME big data and Spark extensions. With them you can run a workflow on a Spark cluster or on a big data platform rather than on a classic machine, using the big data and/or Spark dedicated nodes. This performance extension is the latest addition to the KNIME commercial landscape. Matching the quality of the youngest extension, Spark and big-data nodes are constantly under development trying to keep up with the latest releases, latest development news, and newest features in the field of big data and parallel computation.
Agile Data Analytics
In the previous section we started talking about temporary prototypes. This is another one of the many requests by data scientists all around the world: the ability to implement quick and functioning prototypes, albeit not completely refined. This task is very congenial to the nature and structure of KNIME Analytics Platform.
Based on the extended coverage, the many dedicated nodes, the clear GUI, its surprising speed, the data and tool blending features, and the back compatibility, KNIME really is the ideal platform for agile data analytics.
Back-compatibility is a hidden feature, necessary for repeatability, but not immediately visible when opening a platform and building and running a workflow. Back-compatibility is a bit like a good working IT department: if you do not need their help, it means they are doing their work very well.
The KNIME development team has invested a good part of their resources and time over the past 10 years to guarantee that old workflows keep working even when running on the most recent versions of KNIME Analytics platform. At the cost of becoming boring, I would like to repeat that this is a key, though hidden, feature in the data science lab, because it allows for complete and reliable repeatability of old experiments.
The Name
Finally the name. People often ask us what KNIME really means. Well, for this post and only for this post, I can reveal you in secret that KN is the code for the city of Constance (in German of course), where the first nucleus of the KNIME team started; IM is for Information Mining; E was added for phonetic reasons, but you can associate the word Engine to it, if you like. As I said, the secret will be revealed only in this post. If you missed it, you will probably have to wait till 2026 for KNIME’s 20th anniversary.
The second classic question that follows is: How do you pronounce KNIME? We always thought it was clear, given the assonance with the word “knife”. But “we” is made mostly of non-native English speakers who might be wrong about assonance and obvious pronunciations. So, we will end this post with an explanatory video about the pronunciation of the word KNIME.
Thank you!
To conclude I would like to thank all of you for having walked this section of an exciting and rewarding road with us. We wish for many more years helping the data science community in the creative process of investigating data; that is we wish to remain open for innovation for many more years to come.
The KNIME Team
P.S. Check out our previous post dedicated to KNIME anniversary "2006 to 2016", if you haven't yet.