What's New in KNIME Analytics Platform 4.4 and KNIME Server 4.13
Data Apps, Conda Environment Propagation for R, Snowflake In-Database Processing, and more!
Download KNIME
Newly Moved Out of Labs
Library Updates
Data Apps
Data science teams can choose to deploy their workflows as Data Apps* just like they do everything else in KNIME Analytics Platform: using workflows (no coding required). Using widget nodes and components, you can design your desired UI.
Our recent updates have expanded the accessibility and customizability of the resulting Data Apps. They’re now more shareable, either via a link or embedded in a 3rd party application. They’re also now dynamic, so you can choose to make it a multi-step application (as you’re used to) or have one or multiple refresh buttons inside your application to trigger workflows.
See Data Apps in action in these example workflows on KNIME Hub:
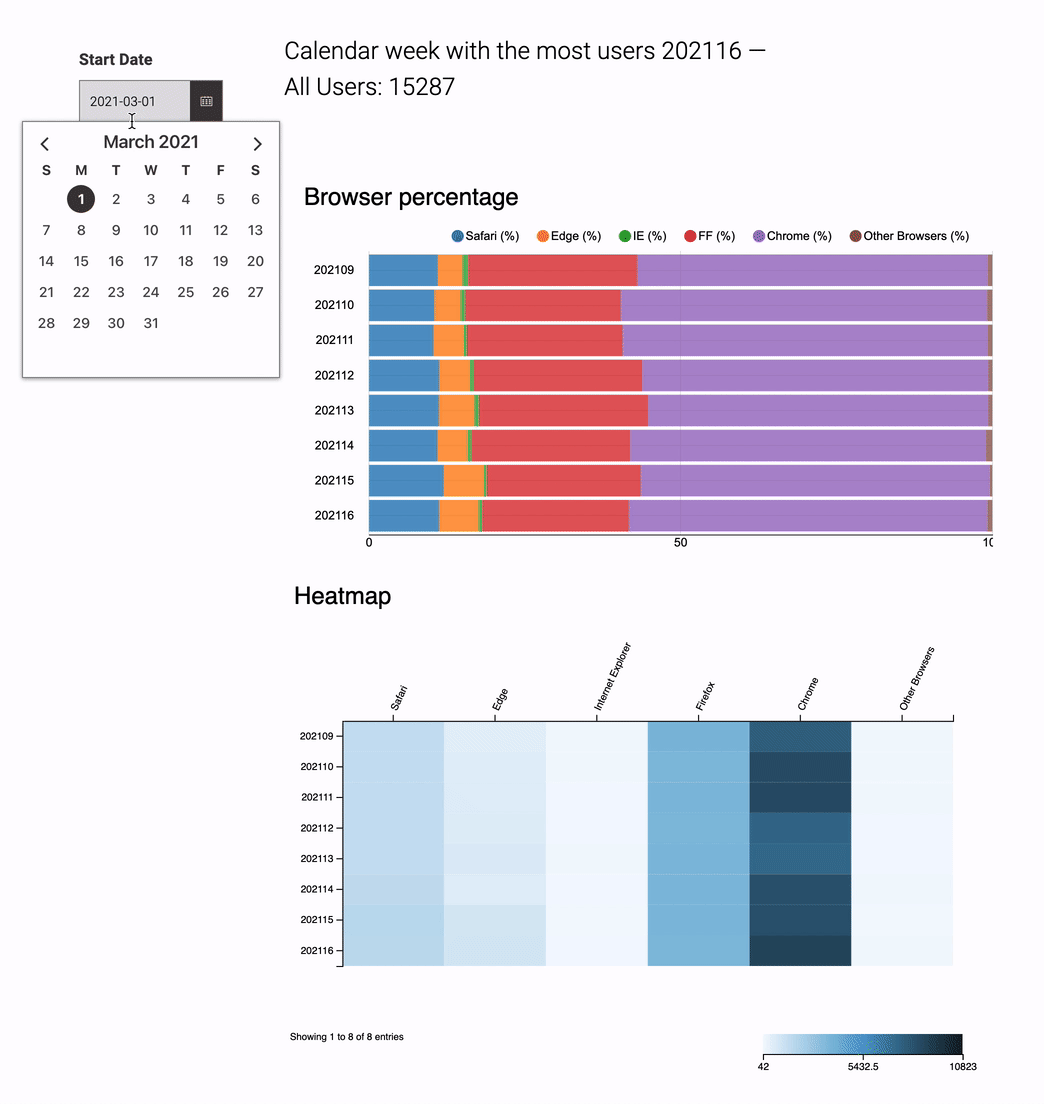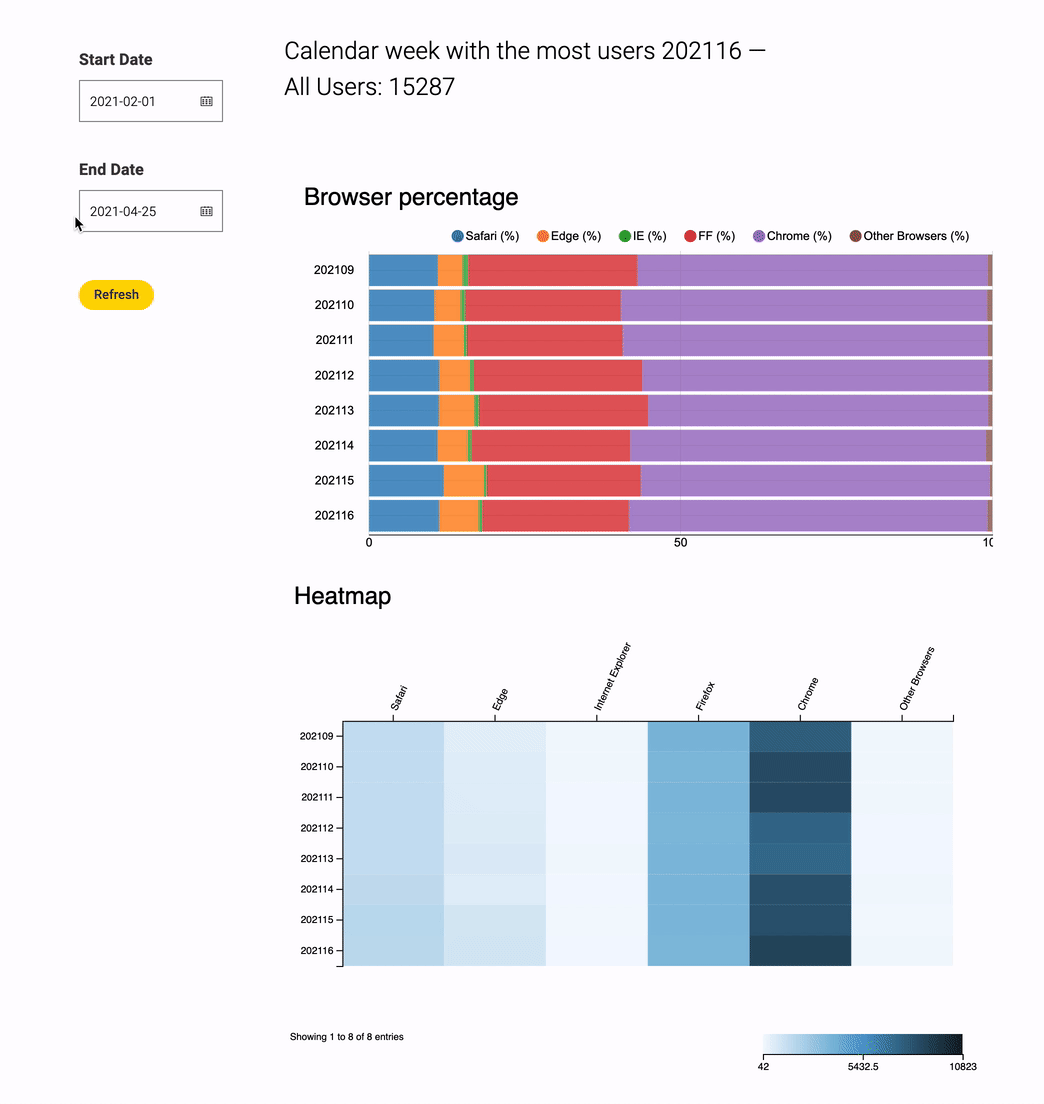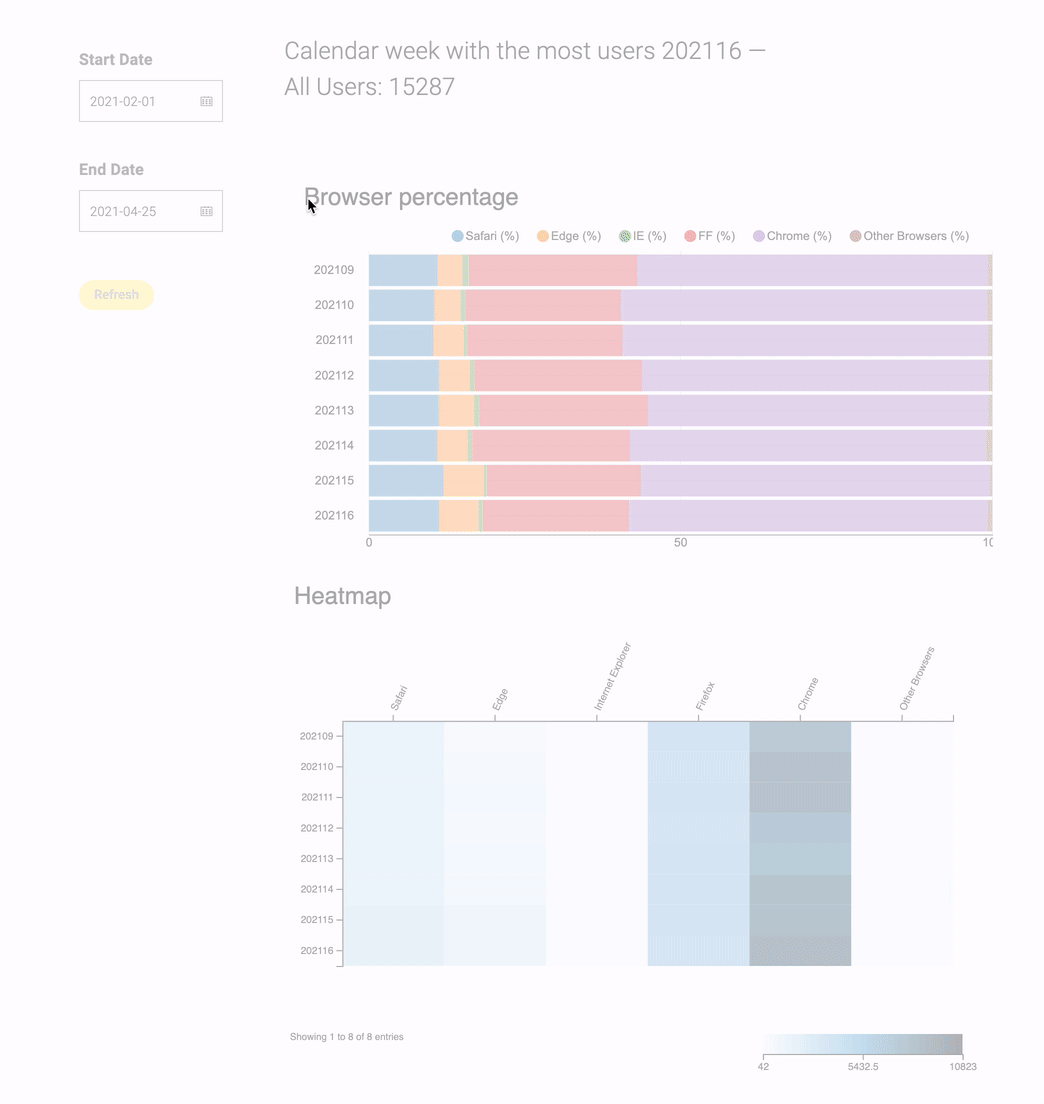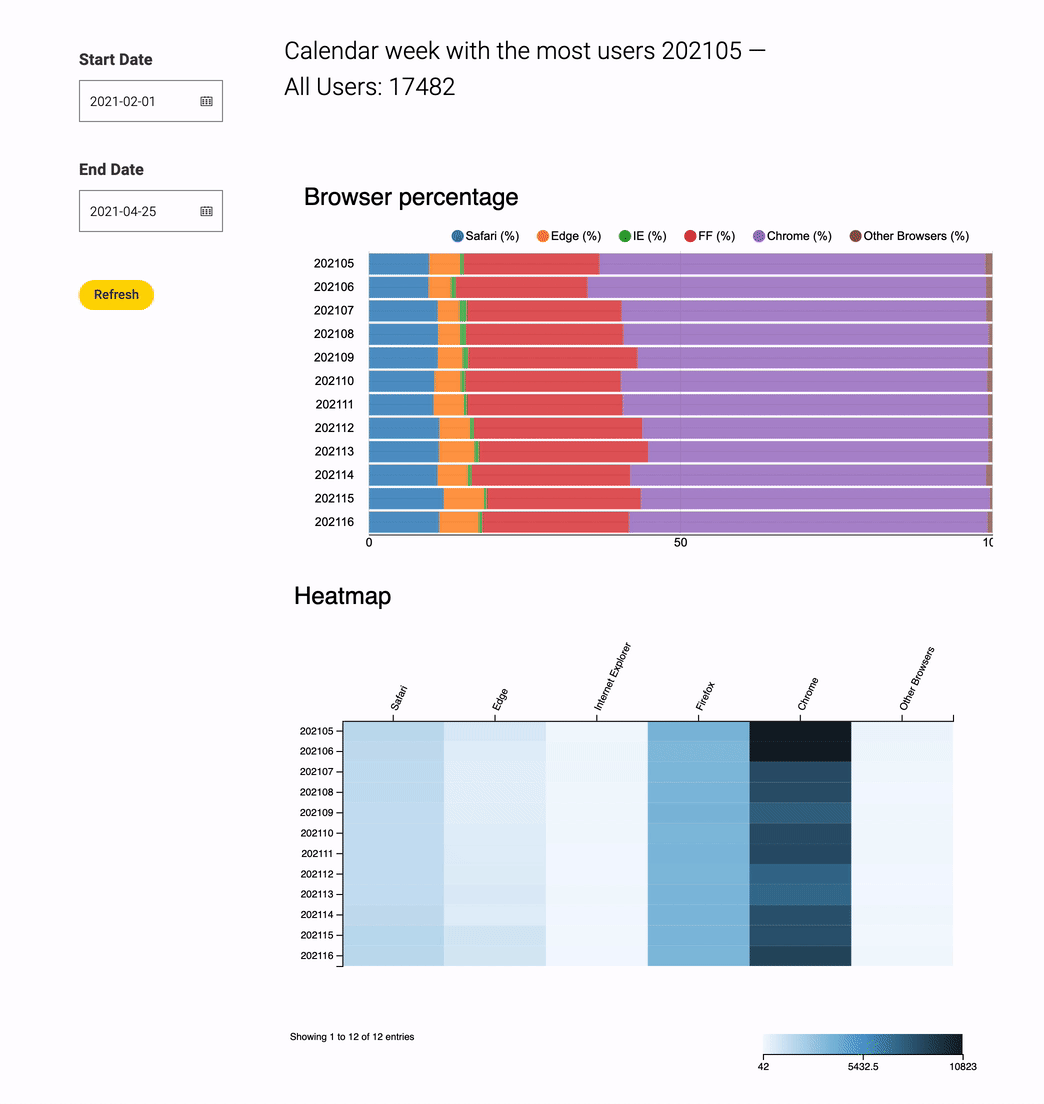
- Browser Usage Single Page Data App Visualization
- Single Page Data App Reactive Views
- Churn Prediction Data App
*Previously known as Guided Analytics Webapps.
Embedded Data Apps, available on Server Large
-
Create shareable and embeddable links that allow end users to run Data Apps without the need to log in explicitly.
-
These links can be embedded in an iframe on any website, making Data Apps accessible from anywhere to everyone.
Dynamic Data Apps
-
Using the new “Refresh Button Widget” node, users can interact with the data on the page and re-run the underlying workflow without leaving the page.
-
Choose to use one “Refresh Button Widget” for the whole page or multiple Widgets. They work independently of each other.
Snowflake In-Database Processing
The Snowflake Connector node provides everything you need to visually assemble SQL queries in KNIME Analytics Platform that are executed in Snowflake.
Details
-
The Snowflake extension contains the Snowflake Connector node that comes with the JDBC driver.
-
Together with the existing database extensions, users can connect to their Snowflake instance and visually assemble database statements that get executed in the Snowflake database.
-
To upload massive amounts of data, you can use the DB Loader node that uploads the data to a Snowflake stage and loads the data into an existing table via the copy command.
-
Example Workflow on KNIME Hub: Load Data into Snowflake
Schedule Retries
There are many reasons why a given scheduled job may fail (e.g., perhaps they temporarily can’t connect to third party data sources). In these cases, you can now specify a number of retries for failed jobs.
Details
-
Having the option to specify a number of retries ensures that the job still gets executed even though the original run failed
Conda Environment Propagation for R
Previously a capability only available for Python, this node ensures the existence of a specific configurable Conda environment and propagates the environment to downstream R nodes.
Details
-
Workflows that contain R nodes are now more portable since you can easily recreate the Conda environment used on the source machine (for example your personal computer) on the target machine (for example a KNIME Server instance).
File Handling
We have a number of new connectors, updated nodes, and updates to the framework itself--and this continues to be a focus.
Benefits
-
The addition of new connectors: The Azure Data Lake Gen 2 Connector together with the SMB Connector are the latest additions to the file handling framework. They allow you to manage, read and write your files in these file systems.
-
Manage files on Azure Data Lake Gen 2 and SMB drives such as SAMBA with the file handling nodes.
-
Read and write text, Excel and other files directly from these file systems.
-
Example Workflow on KNIME Hub: Operations on Remote File System Using SMB Connector
-
-
The rewriting of more nodes to the new file handling framework: The new file handling framework provides a consistent user experience when managing your files across file systems whether locally, on the KNIME Server, in your data center or the cloud. For example:
-
File Reader
-
File Reader (Complex Format)
-
JSON Reader
-
Several table-based utility nodes such as
-
Transfer Files
-
Delete Files
-
Compress Files
-
-
Table Reader
-
Table Writer
-
Support for Path cells in the Column Expressions node
-
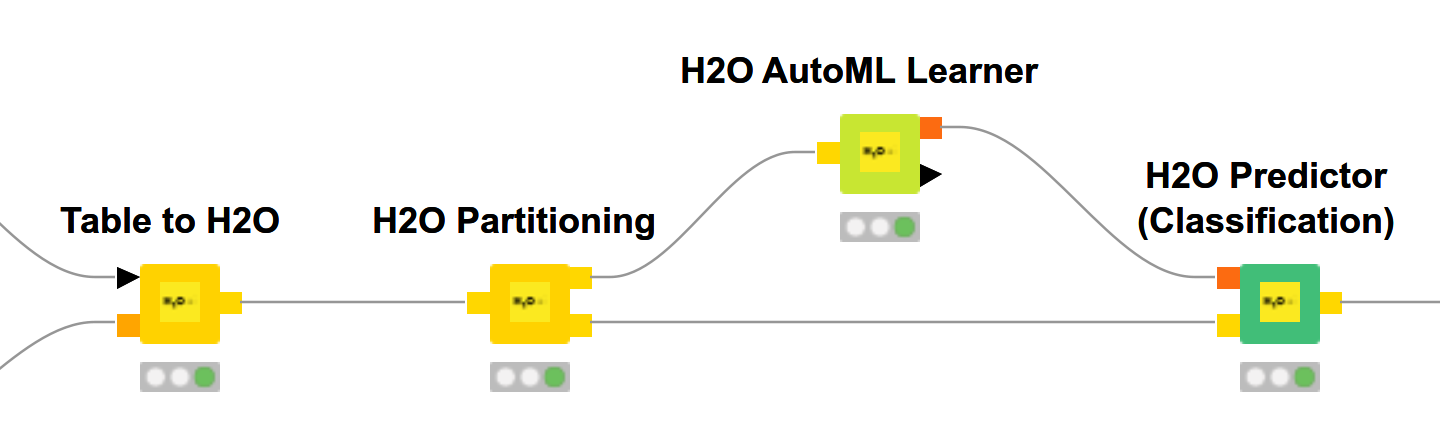
New H2O AutoML Nodes
Two new nodes have been added to the H2O Machine Learning integration: an H2O AutoML Learner for classification and an H2O AutoML Learner (Regression) for regression.
Details
-
H2O AutoML automatically optimizes the hyperparameters of different H2O models.
-
Furthermore, Stacked Ensemble models are created using the trained models. H2O automatically selects and returns the best model.
-
A detailed documentation of the process is provided by H2O.
-
Example Workflows on KNIME Hub
Improved Indexing and Searching Nodes
Index millions of rows and search your numerical or textual data and get results from advanced searches back in milliseconds.
Details
-
The Indexing and Searching extension allows you to create an index from your KNIME data table including complex data types such as text documents.
-
Once the index is created it can be queried using advanced searching techniques such as fuzzy, range and proximity queries to find matches within milliseconds.
-
With the new version you can now store the index in any supported file system, use it across multiple workflows and incrementally update an existing index.
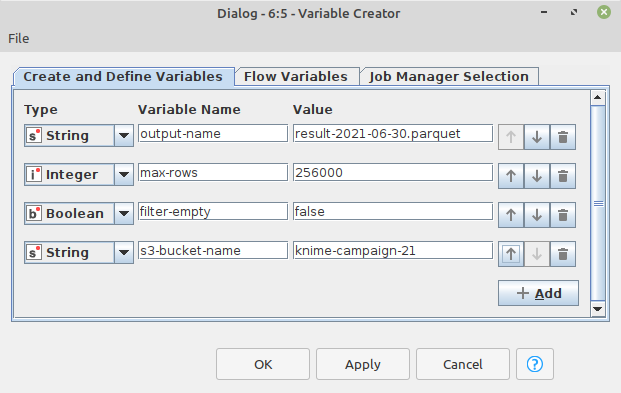
Variable Creator Enhancements
The Variable Creator Node allows you to specify a number of new flow variables at once.
Example
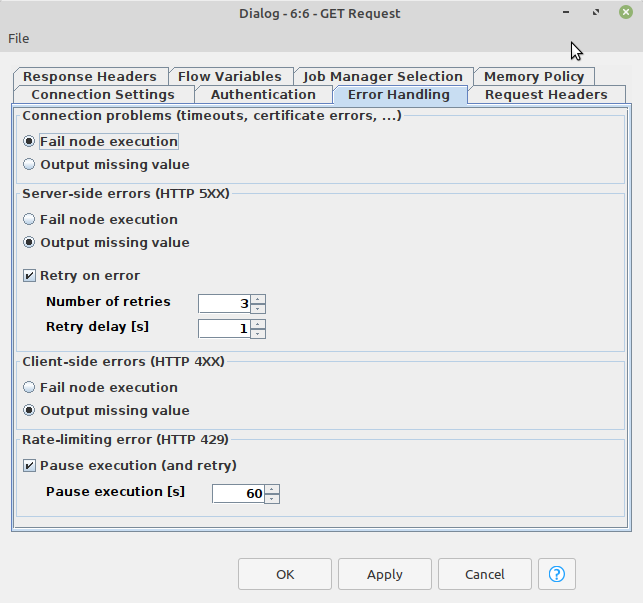
REST Nodes Error-Handling
We’ve made improvements to error-handling for REST Nodes. In the event of node failure for individual requests (e.g., “GET,” “PUT,” etc.) you can now create error handling rules within the node itself, including try-catch and recursive loops.
Details
-
There are many errors that might occur: client-side errors, server-side errors or rate-limiting conditions. All of these can be individually configured, including the number of retry attempts or invocation pausing.
-
Nodes have an additional tab in their configuration dialog to specify the node’s behavior in case of error.
Enhanced Variables Scopes in Loops and Other Contexts
Many programming language features (such as try-catch, if-statements and loops) are available in KNIME Analytics Platform via dedicated start and end nodes which define a scope. Previously, variables defined or modified were not accessible downstream.
Details
The latest updates to variable scopes allow for the propagation of such variables, including feedback of variables in loop iterations. What previously was only possible using “Recursive Loops” is now a built-in “language feature”.
See these features in action in these example workflows on KNIME Hub:
Newly Moved Out of Labs
KNIME Labs is where KNIME-developed nodes are first tested with the community. Moving these out of labs means that they've been fully vetted and are now production ready.
Details
-
Joiner Node: One of the most frequently used nodes is out of labs. You can now specify alternative matching criteria (“Match Any”) and define a default choice for the node.
-
Integrated Deployment Nodes: The nodes that capture and write workflows for continuous and Integrated Deployment have been moved out of labs. New nodes, including the Workflow Reader and the Workflow Summary Extractor have been added.
-
All MongoDB Nodes: MongoDB Reader, Remove, Save, Update and Writer nodes are out of labs. These now support the latest MongoDB version, include a new connector node and improved usability.
-
All PowerBI Nodes: Note that the authentication with Microsoft has been moved out of the node itself. Use the “Microsoft Authentication” node. The “Send To Power BI” node now has the option to define relationships between columns of tables.
Library Updates
Java 11 & Eclipse Update
-
KNIME is based on Java and Eclipse.
-
Previously on Java 8, KNIME now comes with a Java 11 runtime, which is a major new version. Workflows and Workspaces remain compatible with prior versions of KNIME, though we also noted some edge cases of changes in the underlying framework. Details are in the release notes below.
-
Now based on Eclipse 2021-03 (previously 2020-03), addressing many issues that were introduced by macOS Big Sur.
H2O Version 3.32.1.2 Support
The new version contains H2O several bug fixes and enhancements which can be found here.
-
The new version adds support for Spark 3.0 for the H2O Sparkling Water Integration
-
In addition to the already available H2O versions, 3.32.1.2 has been added and will be the new default version
-
The H2O version can be changed under Preferences -> KNIME -> H2O-3
Spark 3 Support
-
We now support Apache Spark 3.0 and the underlying 7.x Databricks runtime environments. Read further about major updates between Spark 2.4 and 3.0 in their release announcement.
-
Easily migrate from an earlier version to Spark 3.0 within KNIME Analytics Platform by simply changing the version number when configuring the Create Databricks Environment or Create Spark Context node.
Release Notes
As outlined above, KNIME Analytics Platform 4.4 is based on an updated version of Eclipse and, more importantly, Java. While extensive testing has been carried out there are chances of some artifacts in the UI, incompatible versions of 3rd party extensions (e.g. via the partner update site), and also slight variations in some of the computations, e.g. regarding date and time handling. These are further outlined below.
Time & Date Handling: Date-time parsing may exhibit slightly different behavior if the input string contains inconsistent data with time zone information. E.g. “2020-06-01T01:00:00+8:00[Berlin/Europe]” is parsed and corrected differently (this timestamp does not exist as Berlin’s timezone is at most +02:00). This behavior might be seen in nodes such as Table Creator and Weblog Reader. Duration To Number node: When the duration value is negative and the granularity is set to millis or nanos the resulting value might differ by +1. There are still some open issues related to the handling of Zoned Date & Time, as the underlying behavior in Java 11 has changed. The node most affected is Extract Date&Time Fields, which under certain conditions did not create backwards compatible results and was therefore deprecated. This FAQ section contains an extensive section on this issue, explaining what the actual problem is, whether you’re affected and how to handle/solve this problem. If you do not select a locale with a country code, the underlying code will use US defaults (like weeks start on Sunday).
XML Parsing Library Change: We no longer use the Xerces / Xalan libraries for XML handling. While no changes are expected regarding WHAT is read, the performance of XML parsing may be different (depending on complexity of the XML and schema/dtd definitions).
Use of XMLBeans and Dynamic Node Factories: API users of any XMLBeans generated libraries, especially extensions of dynamic node factories (e.g. dynamic JS views) and PMML parsers, will need to re-compile their extensions. The binary format of such libraries has changed, hence 4.3.x build artifacts are incompatible with the new version and require a re-compilation.
Updates of Low-Level Libraries: … including Eclipse BIRT, Apache Batik, Apache CXF, Apache POI, Apache Arrow, Chromium.SWT / CEF, and others.
Download KNIME
Download the latest version of KNIME and try out the new release features.