Here is a summary of the latest changes and release features in KNIME Analytics Platform and KNIME Server. You can download KNIME Analytics Platform 4.1 here.
KNIME Hub
KNIME Analytics Platform
- Navigation in the Workflow Canvas
- Machine Learning
- Components
- Guided Labeling
- Nodes, Nodes, Nodes
- Big Data
- KNIME Database Extension
- Community & Partner Extensions
- Technical Improvements
KNIME Server
See the full list of changes in the changelog.
KNIME Hub
Private & Public Spaces
We recently introduced the concept of “Spaces”, which are essentially containers to better separate and organize your work. You have two to start with: public and private. In your private space, you can organize and access all your work conveniently in one easy to use location. You can upload workflows you don’t want to share publicly yet to your private space, take it with you, and continue updating and working on it wherever you go.
Access to Components
Not only has organizing workflows become more convenient, the KNIME Hub helps you build your workflows more quickly and easily by giving you access to components. Upload your component to the public space - therefore sharing it on the KNIME Hub - and provide your colleagues, friends, and the KNIME community with ready-made building blocks to help them easily achieve repetitive or difficult data science tasks. Components uploaded to public space are searchable. In fact, there are now hundreds of them available on the KNIME Hub to help you work more efficiently.
Learn more about the KNIME Hub here.
KNIME Analytics Platform
Navigation in the Workflow Canvas
Browsing and modifying a workflow just got easier! By using Ctrl-F (Command-F on Mac), you can now search for nodes within an active workflow by name, ID, or description. The workflow canvas now has a magic border, which allows you to add new nodes. And even if your workflow is big, there will still be enough space! Also note the file menu, which now lists the most recently opened workflows in your workspace.
Machine Learning
Binary Classification Inspector node
When it comes to model selection, finding the best model to fit your specific use case can be hard. With binary classification problems, it's essential to adjust the classification threshold to optimize the model to your classification task. The new Binary Classification Inspector node and its interactive view helps you compare binary classifiers by applying the best thresholds for each different machine learning algorithm. Customize everything from the threshold to the background color with this new addition to the ML Interpretability extension.
Find an example workflow demonstrating the Binary Classification Inspector node on the KNIME Hub.
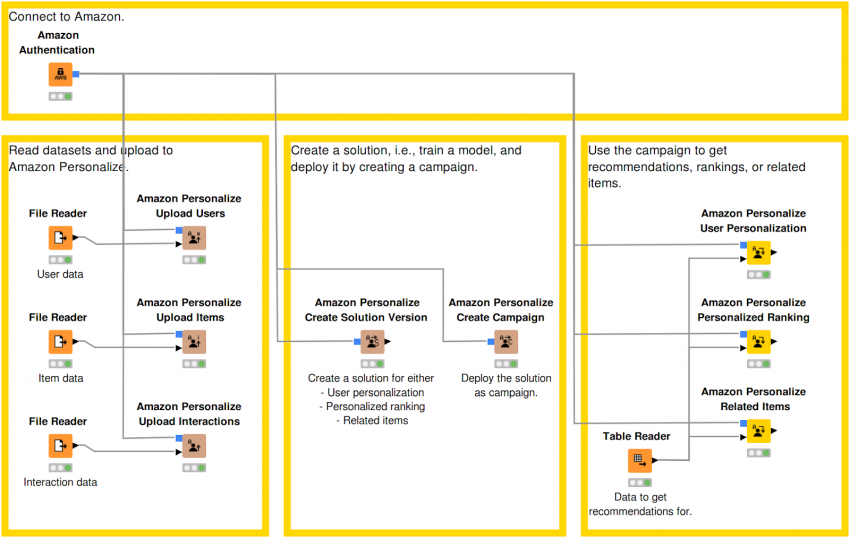
AWS Personalization Service
With this release, we’ve extended our integration of Amazon Web Services (AWS) by adding the Amazon Personalize service. This service allows you to easily build recommendation models, which can then be used to get personalized recommendations. Note: this is a paid service and requires AWS credentials.
Components
Editing a shared component on the KNIME Hub or your local workspace can now be done by double clicking the component. Additionally, the component description can now be conveniently modified using the Component Description view - including the ability to choose custom component icons and categories.
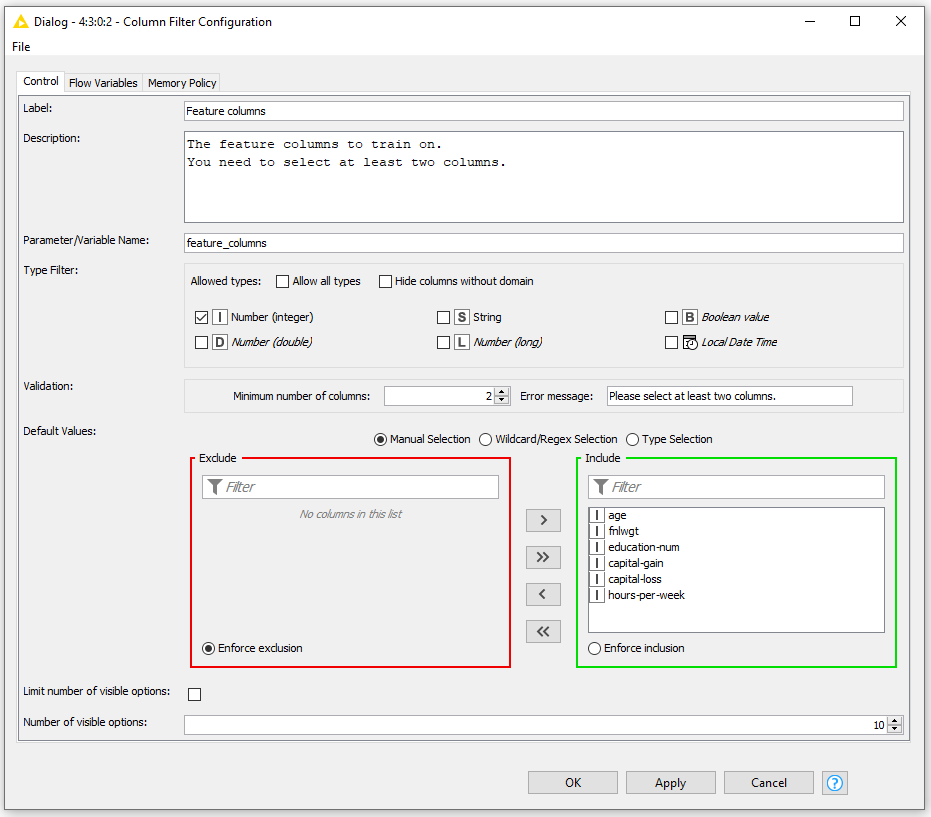
Input Filtering and Validation
The Column Filter Configuration and Column Selection Configuration nodes have been extended, allowing you to specify which types of columns the users of your component are allowed to select in the component dialog. In the case of the Column Filter Configuration node, it’s now also possible to require a minimum number of selected columns.
Guided Labeling
Many machine learning algorithms require a lot of labeled training data, which is usually expensive to come by. With guided labeling we aim to provide two complementary approaches to label your unlabeled data - enabling you to harness your favorite machine learning algorithm.
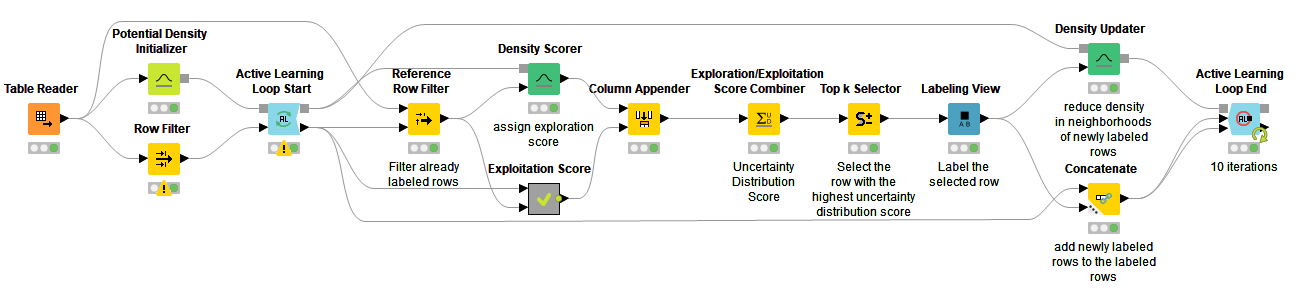
Active Learning
In active learning a machine learning model is trained interactively by iteratively asking the user to provide labels for the data points that are most informative to the model of choice. To ensure that your model makes the best use of the available data, we have nodes for both exploitation of the model’s uncertainty as well as exploration of the feature space.
Find an example workflow demonstrating active learning for document classification on the KNIME Hub.
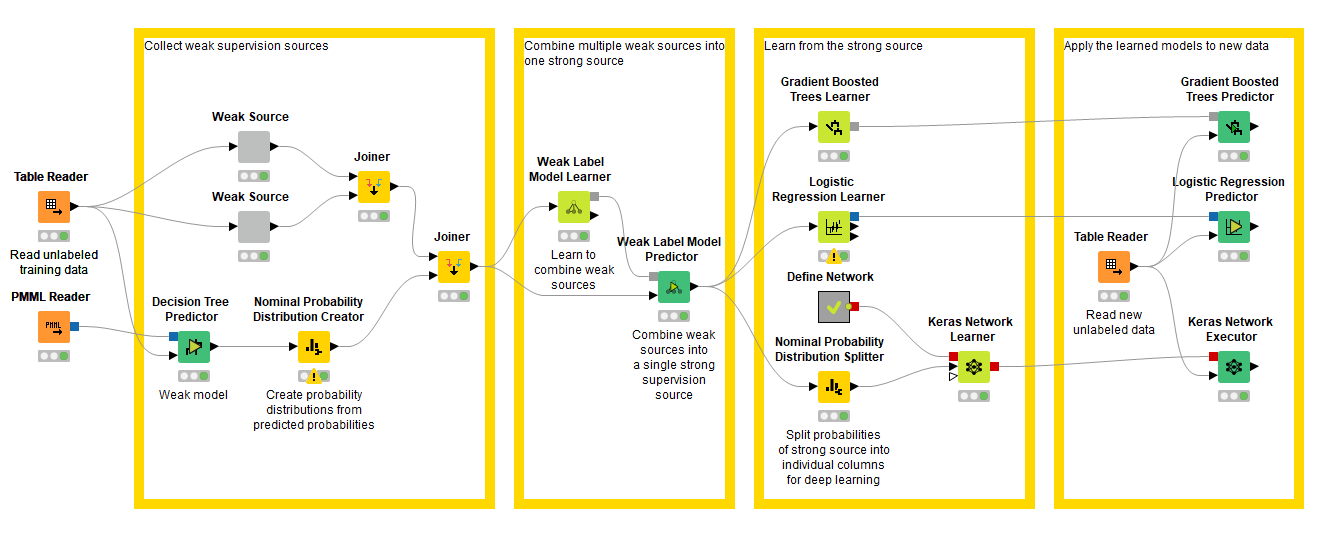
Weak Supervision
Weak supervision involves combining multiple sources of weak supervision into a single probabilistic label, which can be used with the Gradient Boosted Trees and Logistic Regression Learner nodes. A weak supervision source can be anything from a model trained on a related dataset, an existing base of knowledge, or a user that labels data using the active learning nodes. With this release we've added the KNIME Weak Supervision Extension.
Find an example workflow demonstrating weak supervision for document classification on the KNIME Hub.
Nodes, Nodes, Nodes
MDF
MDF (Measurement Data Format) is a binary file format, which has become a de-facto standard for measurement and calibration systems. Its purpose is to store recorded data for post-measurement processing. With the KNIME MDF Reader node you can read these files in your KNIME workflow. In the configuration dialog you can select relevant data channels, choose from the offered filter options to read specific time frames, and select from the offered resampling strategies to harmonize measurements that have been recorded with different frequencies.
Power BI
The new Send to Power BI node allows you to conveniently upload your data created with KNIME to Power BI. Simply use the OAuth based authentication via the node's dialog and select the workspace, dataset, and table you want to upload your data to. After executing the node, all your data will be available in your Power BI dashboard.
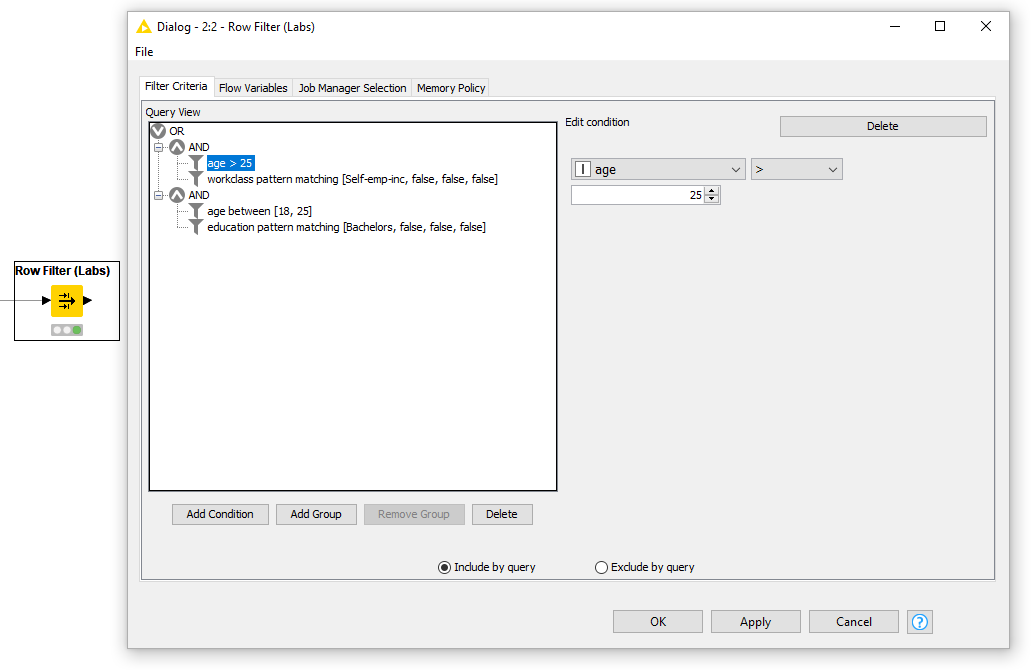
Row Filter (Labs)
This new Row Filter (Labs) node allows you to filter rows based on complex queries comprising conditions on multiple columns - including the row index and row ID. These are easily constructed in an interactive dialog that allows you to choose from a number of different conditions depending on the type of the selected column. This new node can be found in the KNIME Labs Extensions and you should try it out if you want to filter your data based on multiple conditions.
Webpage Retriever
This Webpage Retriever node issues HTTP GET requests and parses the requested HTML webpages. For example, you can use the XPath node to further process the retrieved webpage and extract the information you want. This node also lets you extract cookies from webpages or include cookies in the request.
Top k Selector
The Top k Selector node allows you to select the top k rows according to a sorting criterion specified in the node dialog. It was formerly known as the Element Selector node from our old Active Learning extension. But in addition to moving it to the core KNIME nodes, we’ve also completely rewritten it. It’s now much faster and more flexible, allowing you to specify sorting criteria on arbitrary column types as well as sorting by multiple columns.
Big Data
Databricks
The new Create Databricks Environment node allows you to connect to your Databricks cluster running on Microsoft Azure or Amazon AWS cluster as well as visually interact with Databricks Delta, Databricks File System, or Apache Spark.
Google Cloud Support
With the addition of the Google BigQuery Connector and the Google Cloud Storage Connection nodes, you can now interact smoothly with popular Google Cloud services such as Google BigQuery, Google Cloud Storage, and Google Cloud Dataproc.
Find an example workflow demonstrating the Google BigQuery Connector node on the KNIME Hub.
Apache Knox Support
We now support Apache Knox - the application gateway for interacting securely with REST APIs and UIs of Apache Hadoop interfaces. With this release you can work with Apache HDFS, Apache Hive, and Apache Spark behind an Apache Knox gateway.
KNIME Database Extension
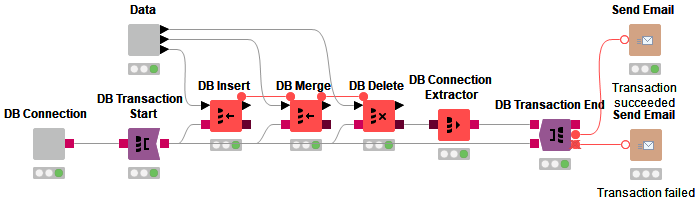
With the introduction of our improved Vertica and Athena Connector nodes, migration of our existing database connectors to the new DB framework is now complete. We’ve also added several new utility nodes, such as a DB Connection Extractor and Closer node. A big improvement is support for transaction management. You can now specify database transaction boundaries via well-known KNIME usage patterns using the DB Transaction Start and DB Transaction End nodes.
Find an example workflow demonstrating the DB Transaction node on the KNIME Hub.
Last but not least: we’ve added various new rules to the workflow migration tool, which now notifies you if a workflow contains nodes that can be migrated to a newer version.

Community & Partner Extensions
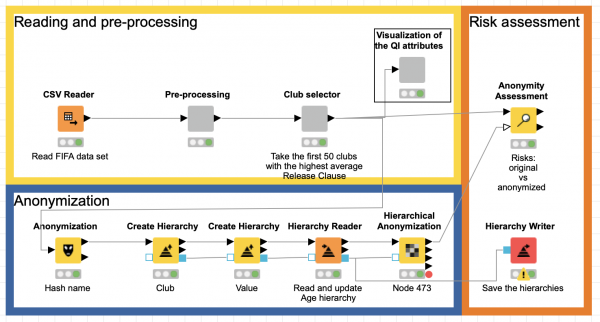
New Partner Extension: Redfield Privacy Nodes
The new privacy extension by our trusted partner Redfield, allows you to anonymize critical data as well as assess the quality of the anonymization applied to datasets. It provides nodes for basic anonymization, complex hierarchical anonymization, and privacy assessment, based on the powerful ARX anonymization toolkit. Learn more in this KNIME blog post.
Technical Improvements
Dynamic Ports
Tired of stacking Concatenate nodes, just because you want to combine more than two tables? In this release, you’ll find a handful of nodes that allow you to add and remove ports based on your needs. Look out for nodes with three black dots in the bottom left corner - this indicates that those ports are modifiable.

New Flow Variable Types
KNIME Analytics Platform 4.1 introduces new types of flow variables. The tried and tested flow variable types string, integer, and double are now complemented by the new boolean, long, and array types. Many flow variable handling nodes, such as TableRow to Variable, support these new types. Also, each node in KNIME can be controlled by these new variables, e.g. filtering a number of columns is possible using an array variable.
KNIME Server
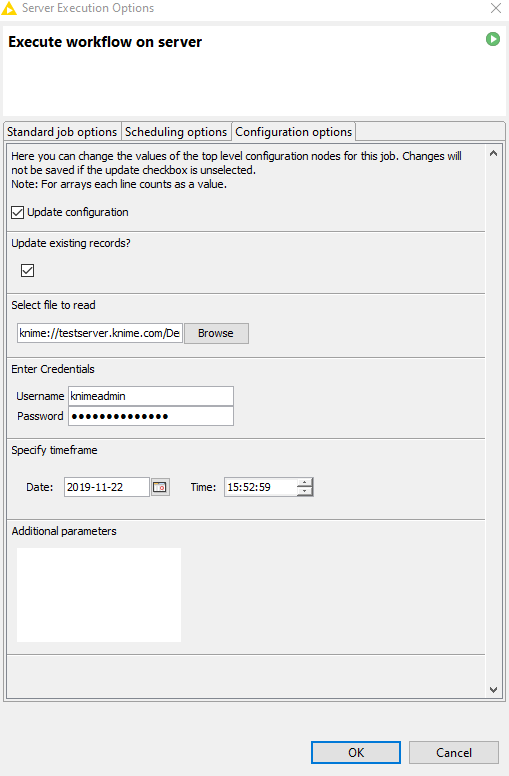
Configuration Dialogs
You can now access the setting values for configuration nodes (introduced in KNIME Analytics Platform 4.0) from the KNIME Server execution dialog. This means you can pass configurations and other values to a job - either for ad-hoc execution or for running on a schedule.
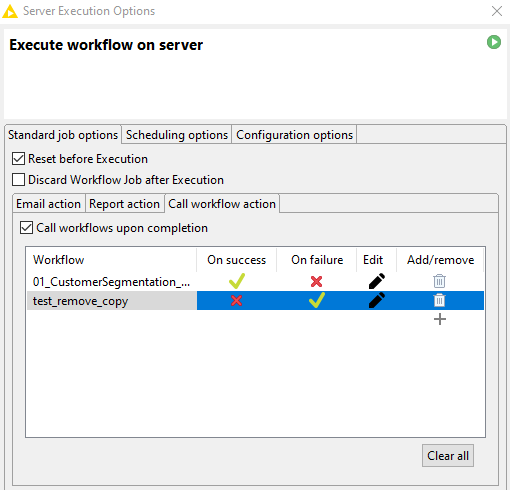
Call Workflow Action
Another new addition to the KNIME Server execution dialog enables you to call one or more new workflows once the current workflow is finished. On top of that, those additional workflows can be called conditionally: you decide whether they should be executed if the original workflow finishes successfully, fails, or both. This gives you a convenient and easily accessible way to organize and structure your all your jobs.
Enterprise Features
OAuth/OpenID Connect
KNIME Server now supports Single Sign-On (SSO) by authenticating users with an Identity Provider with OAuth/OpenID Connect capability. If set up for KNIME Servers, SSO is also supported for connections from KNIME Analytics Platform clients.
For the KNIME WebPortal, this means that OpenID Connect enabled users are redirected to the configured Identity Provider, where they can log in using their existing credentials and approve KNIME Server accessing the users’ information according to the server configuration. After successful authentication, they are redirected back to KNIME Server.
When connecting to KNIME Server from a KNIME Analytics Platform client, authentication also takes place in a browser window.
Server Managed Customization Improvements
Server Managed Customizations is an existing feature we’ve tweaked for this release. Among other things, you can now set multiple update sites via Server Managed Customizations as well as deactivate the default ones. This comes by popular request from many of our enterprise customers, whose users have been unable to connect directly to our own update sites due to proxy restrictions. With Server Managed Customizations, you can now host one or more update sites in your own network, giving easy access to all users who need to install additional extensions.
We hope you like the new release features and provide us with lots of feedback!