Here are some of the changes, new tools and integrations, and new views in both the open source KNIME Analytics Platform and our commercial products.
You can upgrade an existing KNIME Analytics Platform 3.x version either by opening KNIME and choosing the Update option in the File menu or by downloading it from scratch from the download page.
KNIME Analytics Platform
- New Statistics Nodes
- Jupyter Integration
- XGBoost Integration
- Google Authentication and Google Drive Connectivity
- Updated Tableau Integration
- Usability Improvements
Guided Analytics and New Views
- Heatmap
- Hierarchical Cluster Assigner
- Tile View
- CSS Editor
- Interactive Layout Editor and Nested Wrapped Metanodes
Big Data
KNIME Server
- Distributed Executors
- Remote Workflow Editor (Preview)
- Management Services for KNIME Analytics Platform: Customization
- Performance Enhancements
- Monitor Job Execution Time
Previews
See the full list of changes in the changelog.
KNIME Analytics Platform
New Statistics Nodes
Fans of stats tests can rejoice! We’re continuing to expand the KNIME statistical toolbox and have added three new statistical testing nodes: Friedman Test, Kolmogorov-Smirnov Test, and Proportion Test.
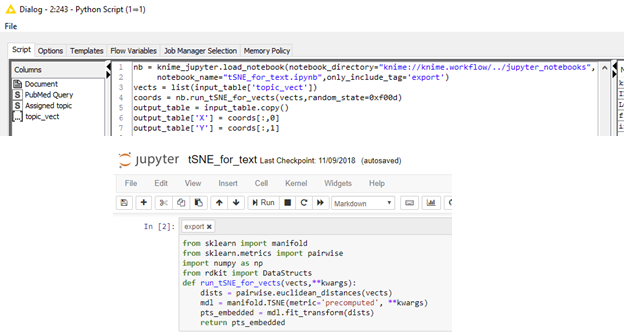
Jupyter Integration
KNIME has had good support for calling/using Python for a while now, and we continue to improve it. For v3.7 we have added support for importing and running code from Jupyter notebooks. So now your code can stay in Jupyter but still be used from within your KNIME workflows; you no longer need to copy/paste code between the notebook and KNIME.
XGBoost Integration
We have added support for the fast, powerful, and very popular, XGBoost machine learning library. You can now use XGBoost’s Linear Ensemble or Tree Ensemble learners for either classification or regression in your KNIME Workflows.
Google Authentication and Google Drive Connectivity
The new Google Drive Connection node allows you to use the files you have stored in Google Drive together with the KNIME Remote File Handling nodes. The node supports reading from and writing to both “My Drive” and “Team Drive”. The authentication nodes have been reworked to support various services, including Google Sheets, Google Drive, and Google Analytics.
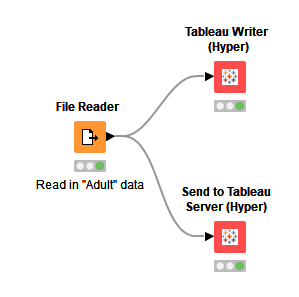
Updated Tableau Integration
We’ve extended our integration with Tableau to add support for our new Date and Time types, to append to existing extracts, as well as to support the Hyper format: you can now write Hyper files as well as sending them directly to a Tableau server.
Usability Improvements
Zooming with the Keyboard
Last release we added the option to zoom into/out of the workflow editor using the mouse. We’ve added keyboard shortcuts for that now as well: CTRL + and CTRL - (Command + and Command - on the Mac) are the magic keys.
Guided Analytics and New Views
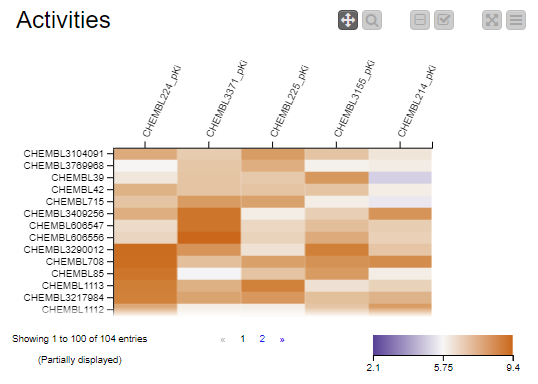
Heatmap
The new Heatmap view provides a nice compact visual representation of numerical data and can make it really easy to spot patterns in the data. The view allows customization of the color map and can interact with other views via the standard selection mechanism.
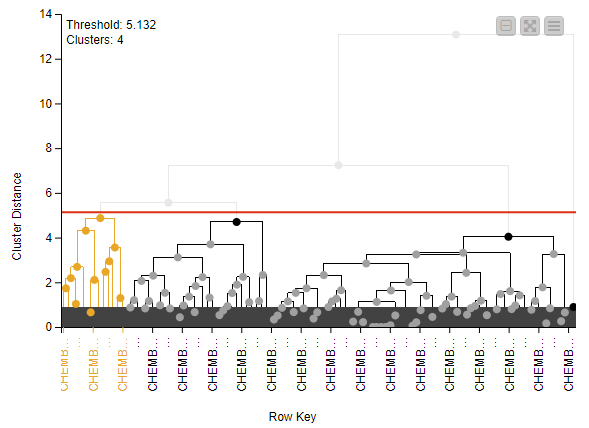
Hierarchical Cluster Assigner
The Hierarchical Cluster Assigner provides both a visualization of a hierarchical cluster dendrogram and allows the user to interactively set the threshold that determines the number of clusters. The dendrogram can also interact with other views via the standard selection mechanism.
Tile View
The new Tile View provides an alternate view of the data in a KNIME table. It’s analogous to the interactive Table View, but is particularly well suited to viewing datasets that include images or other graphics. (In 3.7.0 this view is called "Card View" but due to a trademark clash it will be renamed to "Tile View" starting with 3.7.1).

CSS Editor
Sometimes you want to exercise fine control over the styling of the JavaScript views in your KNIME WebPortal applications (or in Composite Views in KNIME Analytics Platform). We support this by allowing you to specify CSS that is applied to style JavaScript views. This node provides a syntax highlighted editor with auto-completion for editing that CSS.
Interactive Layout Editor and Nested Wrapped Metanodes
These are two related components that make it easier to construct complex interactive views. The first part, the new interactive layout editor, is our next step in making it easier to specify how individual JavaScript views are laid out in a WebPortal page or wrapped metanode composite view: you can now use a drag and drop interface to layout your page. We’ve also added the ability to include wrapped metanodes inside other wrapped metanodes. This allows you to build up a library of wrapped metanodes that contain useful linked views and then easily assemble them to create complex views for visualizing and interacting with datasets.
Big Data
PySpark Node Collection
Yet more good news for people using both Python and KNIME: we’ve added several new nodes that allow you to mix PySpark jobs into your existing Spark workflow. The Python editor allows you to validate the code directly within the cluster for rapid prototyping.
Spark Row Filter
The new Spark Row filter provides you with a rich user interface that allows you to create complex hierarchical filter conditions.
Apache Livy Support
The KNIME Extension for Apache Spark now supports Apache Livy in order to control Spark jobs in your big data environment. Since Livy is part of most distributions such as Hortonworks HDP, Azure HDInsight and Amazon EMR you can start to visually assemble and control your Spark jobs without any installation requirements. For Cloudera we provide CSDs that provide an easy installation via the Cloudera Manager.
Support for Spark 2.4
With this release we add support for Apache Spark 2.4.The only thing you need to do in order to benefit from all improvements in the latest Spark version in your existing workflows is change the Spark version in the Create Spark Context node to 2.4 and re-execute your workflow. As simple as that. We have also updated our Local Big Data Environment as well as the H2O Sparkling Water integration to work with Spark 2.4.
KNIME Server
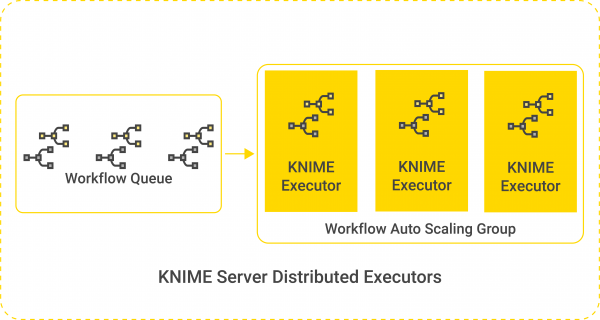
Distributed Executors
The KNIME Server Distributed Executor functionality is now feature complete. It allows KNIME Server to scale workflow execution by adding (or removing) executors that can each run one or more workflows.
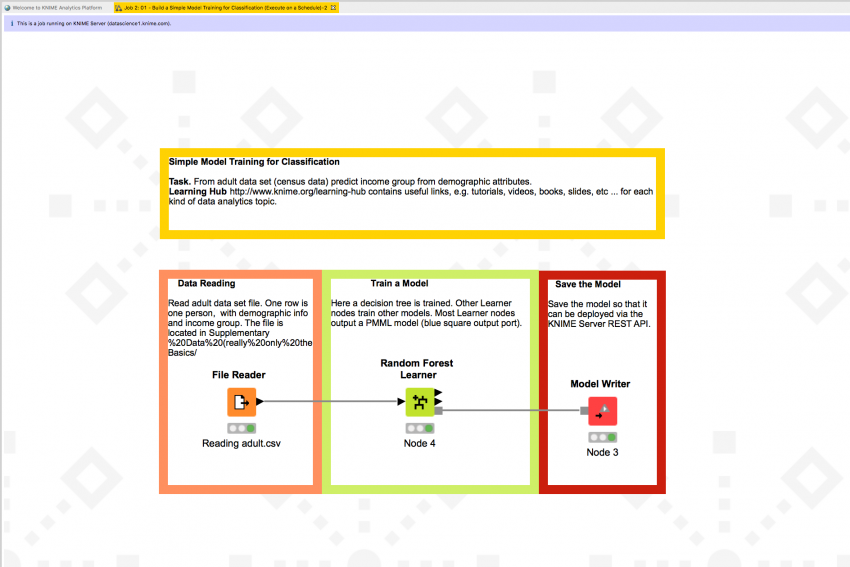
Remote Workflow Editor (Preview)
The Remote Workflow Editor allows KNIME Analytics Platform users to view, edit, and execute workflows on KNIME Server. Take advantage of powerful server hardware, get direct access to protected resources like databases, and monitor the progress of key workflows as they’re executing.
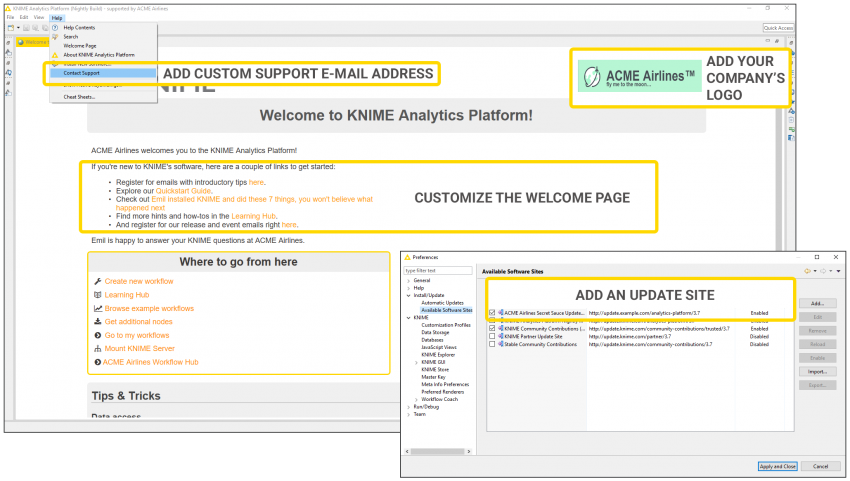
Management Services for KNIME Analytics Platform: Customization
We’ve expanded the possibilities for defining centralized KNIME Analytics Platform customization profiles: you can now use customizations to do things like add messages and links to the Welcome Page, add a company logo, and add custom support email addresses. The new functionality allowing you to define an additional update site makes deployment of your custom-developed KNIME nodes easier.
Performance Enhancements
We made some performance enhancements to the KNIME Explorer, so it’s faster when you’re browsing KNIME Server from your favourite coffee shop. At the same time we took the opportunity to enable a much requested feature: it’s now possible to copy multiple files from your Analytics Platform to KNIME Server. The feature is enabled by default for new server mountpoints, or you can click ‘Use REST’ in the mountpoint configuration dialog for already configured KNIME Servers.
Monitor Job Execution Time
It’s now possible to add a maximum execution time for workflows running on KNIME Server, and there is new information in the REST API that allows you to see how long a workflow takes to run.
Previews
New Database Framework
We have listened carefully to our users and are proud to present to you a preview of the new database framework that incorporates a lot of your valuable suggestions. The new database integration is packed with lots of improvements that you requested such as flexible type mapping, better schema handling, improved driver management and rich SQL editors with the possibility to evaluate the query in the node dialog.
We have rewritten the backend to improve stability and performance, adding features like parallel connections and supporting for streaming execution.
With this release we have migrated all existing database nodes and have revised every node to improve usability. For example, the new DB Row Filter node has support for hierarchical filtering conditions and even allows you to fetch the unique values for the column you want to filter on.
We have also added some long-requested nodes such as new connectors for Oracle and Microsoft Access as well as the DB Merge node that automatically inserts new rows or updates existing rows in the database depending on the selection criteria.
We hope you like the new framework and provide us with lots of feedback!