
Maintenance is a tricky business: you’re always treading that fine line between cost optimization and risk of equipment malfunction – with potentially catastrophic consequences.
Even modern predictive maintenance techniques benefit from data analytics: by knowing when the readings from sensors on critical machinery components are anomalous, failures can be predicted with enough lead time to take cost effective remedial action.
Producers – whether of goods or energy – need to be increasingly competitive to protect their market share. Strong competition means that machinery must operate at peak performance – for as long as possible, without interruptions. So, when even planned stoppages and replacement parts are considered no better than a necessary evil, how can companies ensure that maintenance occurs at exactly the right time? Answer: when they know about impending issues far enough in advance to take appropriate action.
Today’s typical manufacturing plant is a hugely complex array of robotic components and automated systems finely tuned to work together. Critical parts and subassemblies are monitored for proper functioning, with sensors providing data at regular intervals. Based on readings taken while parts were known to function correctly, a model is trained to detect anomalous data, thereby predicting impending breakdowns.
Results:
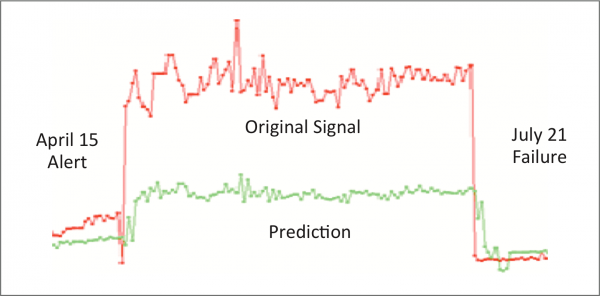
Breakdowns are accurately predicted, alerts inform competent teams many weeks ahead of a mechanical failure. Gradations in alert severity can be recognized and acted upon, based on criticality.
- Prediction in this use case up to 10 weeks before breakdown
- Escalation of maintenance actions e.g. from email to siren to complete system shutdown
- Establishment of accurate, customized preventive maintenance program

Data taken from the sensor monitoring system are read into a Guided Analytics KNIME workflow, which is scheduled to run every day at 3:00 AM on a KNIME Server hosted in the cloud. The model is applied and the deployment workflow calls PMML models, which assess what type of either a first or second level alert should be activated in the case of an anomaly.
In the deployed Guided Analytics application, the first level alert is generated by applying the prelearned PMML models. In a second step those first level alerts are combined and analyzed to report the second level alert. In the case of first level alert the REST service then enables the action - an email to be sent or even a siren to start. If a critical anomaly is detected in form of a second level alert, even a system shutdown can be invoked.
Guided Analytics delivered on KNIME Server / KNIME Server in the Cloud made vast computational resources available to deploy predictive analytics on sensor data, predicting breakdowns up to 10 weeks in advance and setting off appropriate alerts to competent recipients.
Try it out for yourself!
Access reference workflows and data from within KNIME via the Examples Server:
50_Applications/40_Anomaly_Detection
Download Innovation Note here: